Chapter 1 - Historical development and related work
I have had my results for a long time: but I do not yet know how I am to arrive at them.
Karl Friedrich Gauss
In 2003 a study was conducted [lyman03howmuch] that tried to estimate how much new information is created each year. The conclusion was that the world produces between 1 and 2 exabytes of unique information each year, roughly about 250 megabytes for each human being. This amount of information affects most of us in our daily life as we constantly find ourselves overwhelmed by it in many different forms. Think of all TV programs there are to choose among. Which news stories are worth paying attention to? Look at all the new email that keeps on arriving to the inbox? Which restaurant to eat lunch at? And what to eat at the restaurant? Which is the right gift? Which is the right movie to rent? What book, cd or movie to buy from Amazon? A commonly used term for these problems is information overload , something that will happen to all of us sooner or later.
Since ninety-two percent of all the information is stored on magnetic media, primarily hard disks, the research and development of computerized tools for storing, organizing and searching information is highly needed, and indeed, in the field of information retrieval and information filtering , this has been an issue of interest for more than half a century. Applications have been developed in both fields that are suited for different data domains. In the field of information retrieval applications such as search engines for the Web and text-retrieval applications that searches large text-document collections have been developed. In the field of information filtering we have spam filters that filters incoming mail and makes sure no unwanted mail arrives in our mailbox. And from both fields we have recommender systems that retrieve and filter information by figuring out what our needs are, and uses this knowledge to recommend the information that we will probably have most use of.
Information Retrieval
One definition of information retrieval can be found in the book "Information retrieval" by Rijsbergen [vanrijsbergen79information]
"An information retrieval system does not inform (i.e. change the knowledge of) the user on the subject of his inquiry. It merely informs on the existence (or non-existence) and whereabouts of documents relating to his request."
In its basic form, information retrieval is concerned with finding text-documents that match some search criteria. In a typical information retrieval system the user types in a few keywords, a search query, that best describe the wanted information, the information retrieval system then finds this information by matching the keywords against the contents of information stored as textual data. Examples of information retrieval systems are web search engines like Google [brin98anatomy] that matches search queries against the textual contents of web documents, and returns the documents that best match the keywords, usually sorted according to how much they overlap with the search query and by their link structure. Text and document retrieval applications are by far the most popular use of information retrieval systems. One drawback with the query style for retrieving information is that the users have to type in a new question every time they want to know if new information is available for a subject of interest.
Pioneering work on this matter was done in the late 50's by H.P. Luhn, who was the first to automate the process of information retrieval. The purpose of his work was to make it easier for readers of technical literature to quickly and accurately identify the topic of a paper. This was done by first making the documents machine-readable, using punch-cards, and then using statistical software to calculate word frequencies in order to find significant words and sentences that could be used for abstract creation [luhn58automatic] . In his paper "A Business Intelligence System" [luhn58business] , he also describes a system that manages user profiles that consists of the users interests coded as keywords. The system retrieves and stores information that matches the user profile by comparing the user profile against a database of documents. This approach is similar to what later on will be referred to as information filtering .
Beginning in the 1960's a lot of research was done in the field of information retrieval. One of the major researchers in this field was Gerald Salton, who was the lead researcher of a project called the SMART information retrieval system [salton71smart] . Important concepts like the vector space model , term-weighting and relevance feedback was introduced and developed as a part of this research. The system itself was an experimental text-retrieval application that allowed researchers to experiment and evaluate new approaches in information retrieval. The applications that were developed during these years were proven to perform well on relatively small text collections (on the order of thousands of documents) but whether or not they would scale to larger text collections wasn't clear until after the Text REtrieval Conference (TREC)(*) in 1992. The purpose of TREC was to support research within the information retrieval community by providing the infrastructure necessary for large-scale evaluation of text retrieval methodologies. TREC resulted in large text collections being made available for researchers. TREC is co-sponsored by the National Institute of Standards and Technology and U.S. Department of Defence and is now an yearly event. With the distribution of a gigabyte of text with hundreds of queries, the performance of the retrieval systems could now be judged by their actual performance. New and improved applications could, thanks to this, be developed that were suitable for large text collections. For example, in the early days of the Web, searching the Web was done by using algorithms that had been developed for searching large text collections [singhal01modern] .
The field of information retrieval is still even after nearly fifty years of research a very active and important research field due to the increasing amount of information being generated - not in the least due to the introduction of the World Wide Web in the beginning of the 1990's. The research area has gone from its primary goal of indexing text and searching for useful documents in text collections to include research on modelling, document classification and categorization, systems architecture, user interfaces, data visualization, filtering, language analysis, etc. Some modern applications of information retrieval are search-engines, bibliographic systems and digital libraries. See for example the book "Modern Information Retrieval" [baeza-yates99modern] for a overview of the research in information retrieval with a focus on the algorithms and techniques used in information retrieval systems.
Information Filtering
Today's recommender systems have their origin in the field of information filtering, a term coined in 1982 by Peter J. Denning in his ACM president's letter titled "Electronic junk" [denning82electronic] . In the paper Denning writes that:
"The visibility of personal computers, individual workstations, and local area networks has focused most of the attention on generating information -- the process of producing documents and disseminating them. It is now time to focus more attention on receiving information-- the process of controlling and filtering information that reaches the persons who must use it."
Dennings describes one approach for how to deal with the problem of filtering information being received, called content filters. He describes content filters as a process by which for example the contents of emails are scanned in order to decide what to do with them; discard them or forward them. He ends the letter with a open request that something must be done about the growing problem of how to handle the quantity of information that we produce.
The 1970's was a big decade when it came to databases, which in combination with the falling prices of storage space led to an increasing amount of digital information being available in the 80's. There was also an increasing availability of computers as well as an increasing usage of computer networks to disseminate information. It was probably the beginning of these trends that Dennings had observed and which led to his request for more effective filtering techniques. As a result, there was an increased activity in the research of filtering systems during the 80's and several papers were published on the subject, the paper by Malone et al. [malone87communication] published in 1987 being one of the more influential ones. Their paper discusses three paradigms for information filtering called cognitive , economic and social . Their definition of cognitive filtering is equivalent to the content filter defined by Dennings and is now commonly referred to as content based filtering. Economic filtering is based on the fact that a user often has to make a cost-versus-value decision when it comes to processing information, e.g. "is it worth my time to read this document or email". Social filtering is defined as a process where users annotate documents they have read and where the annotations are then used to represent the documents. Users decide, based on the annotations, if the documents are worth reading. They thought that, if practical, this approach could be used on items regardless of whether or not the contents of the item can be represented in a way suitable for content filtering.
In November 1991, Bellcore hosted a Workshop on High Performance Information Filtering. The workshop brought together researchers with interests in the creation of large-scaled personalized information delivery systems and covered various aspects of this area and its relation to information retrieval. The workshop resulted in a special issue on information filtering in Communications of the ACM [cacm92communications] . One of the articles in the special issue was written by Belkin and Croft [belkin92information] , in it they discuss the difference between information filtering and information retrieval. They come to the conclusion that both techniques are very similar on an abstract level and has the same goal, i.e. to provide relevant information to the user, but define some differences that are significant for information systems; filter systems are suitable for long-termed user-profiles on dynamical data whereas retrieval systems are suitable for short-termed user profiles on static data. The traditional way of retrieving information is to ask a query (short-termed) that is matched against available information. A system can however also build up a user profile (long-termed) which is used in connection with every query, this means that personalization can be done, each answer is adjusted to the users preferences as well as the actual query. The other articles in the special issue give examples for applications of information filtering and extensions to information retrieval.
Collaborative Filtering
Remember to always be yourself. Unless you suck.
Joss Whedon
One article [goldberg92tapestry] in the special issue on information filtering in Communications of the ACM [cacm92communications] took a different approach to information filtering. They implemented their own version of social filtering in a system called Tapestry. Tapestry allowed a small community of users to add annotations such as ratings and text comments to documents they had read. Users could then create queries like "receive all documents that Giles likes". The system relied on the users all knowing each other, so that users could judge from a personal basis or by reputation if the reviewer of a document was trustworthy or not. Two major drawbacks with the system was that it did not scale well to larger user groups (as everybody had to know each other), and the filtering process had to be done manually by the users (the formulation of specific queries). They chose to call their approach collaborative filtering , which also became the name for a new direction in the research area of information filtering.
The new research direction resulted in further research into collaborative filtering, and the development of new collaborative filtering systems, where GroupLens [resnick94grouplens] for Usenet News, Ringo [shardanand95social] for music and video@bellacore [hill95recommending] for movies are among the more notable ones. The main contributions of these new systems were to automate the filtering process of Tapestry and make it more scaleable. By letting users be represented by their ratings on items, the systems could automatically find other users that had a similar type of rating behavior as the active user. Users with similar rating behavior could then become recommenders for the active user on items they had rated and which the active user hadn't rated. This approach was based on the heuristic that users that have agreed in the past probably will agree in the future . As users were no longer required to all know each other the former scalability issue of Tapestry was solved. In other words, the users that were found similar to you would take on the same role as the trusted well-known reviewer in the Tapestry system, with the difference that now you didn't know who the reviewers were, the trust was instead put on the system to find them.
Motivated by the research done into collaborative filtering since the 1991 workshop where Tapestry was presented, a new workshop was held in 1996 by Berkley, this time the topic was collaborative filtering. The workshop resulted in a special March issue of 1997's Communications of the ACM [cacm97communications] , covering the new research into collaborative filtering. It was this year that collaborative filtering got its real major breakthrough in the research community at large and the term recommender system got coined.
While the automated collaborative filtering systems had solved the scalability issue of Tapestry, now allowing a theoretically unlimited number of users that didn't need to know each other, a new scalability issue had manifested. The increasing number of users required an increasing amount of memory and computation time. Breese suggested in [breese98empirical] a model based approach to CF, and therefore decided to divide CF techniques into two classes, memory based collaborative filtering and model based collaborative filtering .
Memory based collaborative filtering techniques were to correspond to the earlier automated CF techniques that required that the entire database of user's ratings on items was kept in memory during the recommendation process. Since the entire rating database is kept in memory, new ratings can immediately be taken into account as they become available. Recommendations for the active user can be produced using variations of nearest neighbor algorithms, memory based CF is for this reason sometimes referred to as neighborhood based CF . These algorithms utilize the whole rating database, to find neighbors to the active user, by calculating similarity between the active user and all the other users in the rating database based on how they have rated items. Users that are found to be similar to the active user are then used as recommenders in the recommendation process. The major drawback with memory based CF techniques is as already noted that they tend to scale very poorly, larger rating databases require more memory and more calculations which slow down the recommendation process.
Model based collaborative filtering techniques, Breese suggested, will on the other hand only use the rating database to construct a model (hence the name) that can be used to make recommendations. The construction of such a model is primarily based on the rating database, however once the model is created the rating database is no longer needed. It is thus not necessary to keep the huge rating database in memory, which typically should improve the performance and scalability issues. But since it is just a model, it may (depending on the model) be necessary to reconstruct it as more ratings become available in order to accurately model the relations of users and items in the rating database. The need to reconstruct the model can be a significant drawback with this approach.
Breese proposes in [breese98empirical] a probabilistic perspective to model based CF, where calculating the predicted value pu, i for an item i for the active user u can be viewed as calculating the active user's expected rating ru, i on the active item, given what we know about the active user. The information available about the active user is the set ur of all ratings given by active user. Assuming ratings to be in the interval ![[R_{min},R_{max}]](image/math0.png) the following formula could then be used to calculate the predicted value:
the following formula could then be used to calculate the predicted value:
![p_{u,i} =
E \left( r_{u,i} \right) =
\sum_{v=R_{min}}^{R_{max}} \left[ v \times P \left( r_{u,i} = v | u_r \right) \right]](image/equation0.png)
Where P is the conditional probability that the active user will give the active item a particular rating. To estimate the probability P , Breese proposes two alternative probabilistic models: Bayesian Networks , where each item is represented as a node in a network and the states of the nodes correspond to the possible ratings for each item; and Bayesian clustering where the idea is that there are certain groups or types of users capturing a common set of preferences and tastes, as such user clusters are formed, and the probability that the active user belongs to each of them is estimated, using the estimated class membership probabilities predictions can be calculated.
Several other probabilistic models have been proposed in the literature, some more advanced than others, such as the work of [shani02mdp] where they see the recommendation process as a sequential decision process and proposes the use of Markov decision chains to create a model. However, they don't report any better accuracy than the models proposed by Breese. Many other non-probabilistic model based CF techniques have been suggested, such as the machine learning techniques found in [billsus98learning] , where artificial neural networks are used together with feature extraction techniques like singular value decomposition to build prediction models. They claim a slightly better result than the correlation based techniques proposed earlier by e.g. GroupLens [resnick94grouplens] .
In 1999 Herlocker and others [herlocker99framework] summarizes what can be referred to as the state of the art of CF. The automated CF problem space is formulated as predicting how well a user will like an item that the user has not yet rated given the ratings for a community of users . An alternative problem space definition is also given where users and items are represented as a matrix where the cells consist of ratings given by the users on the items, the collaborative filtering recommendation problem can then be formulated as predicting the missing ratings in the user item rating matrix [ucf rating matrix] . The most prevalent algorithms used by collaborative filtering techniques are considered to be neighborhood based (which is still true). A framework for performing collaborative filtering using neighborhood based methods is presented and discussed in detail. An important and still widely used extension to neighborhood based collaborative filtering methods called significance weighting is introduced, where the similarity between users is down weighted according to number of co-rated items.
An alternative approach to collaborative filtering is proposed in [sarwar01itembased] where the relationship between items, instead of users, is used. Sarwar et. al developed a new technique that they chose to call item based collaborative filtering , in contrast to the techniques described by [herlocker99framework] which they refer to as user based collaborative filtering . Recommendations are based on what the active user thinks of items similar to the active item, instead of what the neighbors of the active user thinks of the active item [icf rating matrix] . The similarity between items is essentially based on the heuristic that a person's opinion on two items that are similar doesn't vary much .
Many may consider [sarwar01itembased] to be the first time an item based CF technique is described in a public paper, however as early as 1995 a similar approach was described in [shardanand95social] in form of what they called the artist artist algorithm , where they used the similarities between artists to make recommendations. The artist similarities were based on user ratings. However, they reported worse results compared to their other user based algorithm. No references is made to the scalability problem so this was probably just a test to see how well the approach stood up to their user based CF technique
A few years later in the paper [linden03amazon] a description is given of the CF technique used byAmazon(*) , who also holds a patent for the technique they use. A brief and not very detailed description of an item based CF technique that reminds a lot of the one described in [sarwar01itembased] is given.
The technique presented in [sarwar01itembased] has been further extended in [karypis04itembased] for top n item recommendations . They propose an alternative algorithm called item set to item CF where the difference lies in that the item similarity is computed between a single item and a set of items instead of between two single items.
The empirical results for item based CF shown in [sarwar01itembased] show that a model that only uses the 25 most similar items for each item will produce recommendations that are nearly 96% correct compared to a full model that uses all item similarities. Both [sarwar01itembased] and [karypis04itembased] show comparable results against user based CF, but with a much faster computation time and no scalability problems in relation to the size of the user item rating matrix, allowing for better scalability to systems with millions of users and items.
Recommendation techniques
Two prevalent techniques based on the CF recommendation approach that have emerged over the years are user based CF as described in [resnick94grouplens] , [shardanand95social] , [herlocker99framework] and item based CF as described in [shardanand95social] , [sarwar01itembased] , [linden03amazon] , [karypis04itembased] . While both techniques rely on the CF approach where a large group of users ratings are used as a basis to make recommendations, the techniques implement the CF approach in two very distinct ways. The names of the techniques vary greatly among papers ( user based , user to user , neighborhood based , sometimes more specific such as artist to artist etc.), in this paper we have chosen to use the names user based CF and item based CF based on the historical development of CF and the distinctions necessary to make and will use them throughout this paper.
User based Collaborative Filtering
User based CF is a memory based technique for making recommendations where the main task is to find users that are similar to an active user. The users similar to the active user, usually referred to as the active user's neighbors , are used as recommenders for the active user in the recommendation process.
In [herlocker99framework] a framework is presented for performing user based CF (referred to as neighborhood based CF in the paper). The framework presented by Herlocker assumes users have been represented using their ratings on items, and instead focuses on the neighborhood formation and the prediction computation. Herlocker's framework, with additional explanations is as follows:
Weigh all users with respect to their similarity with the active user. Define a similarity function similarity(u, n) that measures the similarity between the active user u and a neighbor n (since user's are represented using their ratings profiles consisting of ratings on items, similarity is computed based on the users rating profiles). The more similar a neighbor is to the active user, the more weight is put on his influence on the final recommendation. One should observe that the introduction of a similarity measure as a weight value is an heuristic artifact that is used only for the purpose of differentiating between levels of user similarity and at the same time to simplify the rating estimation. Any similarity function can be used as long as the calculation is normalized (i.e. similarities lie in a expected interval, which typically is [0, 1] or [-1, 1] ).
Select a subset of users to use as recommenders. The subset of users (the relevant neighbors of the active user) can be selected in many different ways. Simple ways for selecting neighbors is to choose those that have a similarity above a fixed threshold value , or to choose the k most similar users according to calculated similarity or according to number of commonly rated items. While theoretically all users could be used given that similarities have been calculated, selection of a subset is often necessary practically. For example, similarities may be so unreliable that using a subset of the most trusted similarities is highly necessary to get good recommendations.
Compute predictions using a weighted combination of selected neighbors' ratings. The predicted value pa, i for the active item i that the active user u has not yet rated is computed as an aggregation of the rating of each neighbor n for the same item i , i.e.
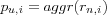 .
.
The user based CF recommendation technique and the proposed more detailed framework thus leaves open the selection of similarity measure, the method for forming neighborhoods and the definition of the 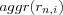 function for making predictions. Much research has been done on possible ways of implementing and varying these parts of the user based CF technique.
function for making predictions. Much research has been done on possible ways of implementing and varying these parts of the user based CF technique.
In general the problem solved by the user based CF technique can be defined as predicting the missing values in a (typically very large and very sparse) user item rating matrix [herlocker99framework] , where each row represents a user and each column represents an item. For example the user item rating matrix given in [ucf rating matrix] shows that Giles hasn't seen the movie Kill Bill.
| The Thing | Land of the Dead | Magnolia | Kill Bill | |
| Giles | 5 | 4 | 1 | ? |
| Buffy | 5 | 5 | - | 5 |
| Spike | 5 | 1 | - | 1 |
| Snyder | 3 | 3 | 4 | - |
ucf rating matrix User item rating matrix where items are movies and cells thus consists of user ratings on movies. Shadowed cells shows which ratings are used when comparing Giles's row of ratings to Buffy's row of ratings. Only movies rated by both users can be considered.
Whom of the other users should Giles trust to make the recommendation? By studying how well Giles's row of ratings in the matrix matches Buffy's, Spike's and Snyder's row respectively, it can be determined who should be trusted, and even to which degree they can be trusted. Trust is in this case simply based on the heuristic that users that have agreed in the past probably will agree in the future , as such Buffy, who's row of ratings is most similar to Giles's row of ratings, should be trusted the most. Spike is difficult to trust as he agrees and disagrees sometimes, and Snyder can't be trusted at all, which doesn't matter however as Snyder hasn't seen Kill Bill and thus can't predict on it for Giles.
Item based Collaborative Filtering
Item based collaborative filtering is a model based technique for making recommendations where the main task is to find items that are similar to an active item. The populations ratings on items is used to determine item similarity. Recommendations are formed by considering the active users ratings on items similar to the active item, usually refered to as the active items neighbors (to be clear, the neighbors in item based CF are items, not users). It is assumed that items have been represented using the users' ratings on the items. The recommendation technique then consists of the following three major steps:
Weigh all items with respect to their similarity to the active item. Define a similarity function similarity(i, j) that meassures the similarity between the active item i and another item j (since item's are represented using rating profiles consisting of users ratings on the item in question, the similarity is computed based on the items rating profiles).
Form the active item's neighborhood of similar items. The neighborhood can either be such that it consists of the most similar items out of all items, independent of wheter the active user has rated them or not, or it can be the set of the most similar items out of those the active user has rated. Typically only a subset of the k most similar items are selected.
Compute a prediction on the active item for the active user using a prediction algorithm that is based on how the active user has rated items in the active item's neighborhood .
The main motivation behind this approach is to overcome some of the problems with scalability and computational performance that are symptomatic for user based CF.
Similar to user based CF the item based CF technique can be defined as predicting the missing values in a user item rating matrix. In [sarwar01itembased] it is proposed that the relations between columns in a user item rating matrix should be considered. Thus, while the problem space is still that of predicting the missing values in a user item rating matrix as defined in [herlocker99framework] , relations between items instead of users is now considered. For example the user item rating matrix given in [icf rating matrix] shows that Giles hasn't seen Kill Bill.
| The Thing | Land of the Dead | Magnolia | Kill Bill | |
| Giles | 5 | 4 | 1 | ? |
| Buffy | 5 | 5 | - | 5 |
| Spike | 5 | 1 | - | 1 |
| Snyder | 3 | 3 | 4 | - |
icf rating matrix User item rating matrix where items are movies and cells thus consists of user ratings on movies. Shadowed cells shows which ratings are used when comparing the movie Land of the Dead's column of ratings to the movie Kill Bill's column of ratings, only ratings by users that have rated both movies are considered.
When predicting the missing rating on Kill Bill for Giles in this case, the prediction will be based on what Giles thinks of movies that are similar to Kill Bill. The similarity between movies is found by matching the column vector of Kill Bill against the column vector of the other three movies. The similarity between items is essentially based on the heuristic that a persons opinion on items that are similar doesn't vary much . As such, since ratings on Kill Bill and Land of the Dead varies the least, among users that have rated both movies, they can be considered similar (and I think we can all agree that both movies have a lot of death , serendipity!). Since Giles thought Land of the Dead was a 4 that might thus be a suitable prediction on Kill Bill for Giles.
Similarity measures
Prevalent throughout the research into collaborative filtering has been the study of similarity measures to use to determine user (and item) similarities. The two most popular types of similarity measures are correlation based and cosine based . In [resnick94grouplens] they suggested the use of the Pearson correlation coefficient as a correlation based similarity measure. [breese98empirical] compared recommendation techniques using the Pearson correlation coefficient and the cosine angle between vectors as similarity measures, the recommendation technique using the Pearson correlation coefficient was found to perform better. The Ringo system [shardanand95social] made use of the mean squared difference and a constrained version of the Pearson correlation to measure the similarity between two users. Their results show that the constrained Pearson performs better compared to the Pearson correlation coefficient and the mean squared difference.
In [billsus98learning] some important issues regarding ( linear ) correlation-based approaches are discussed, which we refer to as the reliability , generalization and transitivity issues.
- Reliability
The correlation between two users is calculated only over items both have rated. Since users can choose among thousands of items to rate, it is likely that the overlap between most users will be small. This has the effect that the use of the correlation coefficient between two users as a similarity measure is in many cases unreliable. For example, correlations based on three items has as much influence in the final prediction as a correlation based on thirty items. It is thus important to somehow take into account the number of items involved in the correlation, a popular solution to this is the usage of significance weighting [herlocker99framework] .
- Generalization
The correlation based methods typically uses a generalized global model of similarity between users, rather than separate specific models for classes of ratings. For example, referring to [generalization rating matrix] where a rating scale of 1 to 5 is used, we see that the two users agree on two movies and disagree on the remaining movies.
The Thing Grudge Andrey Rublyvov Fargo Magnolia Giles 5 5 1 2 1 Spike 1 2 1 2 2 generalization rating matrix User item rating matrix consisting of two users. Note that when Giles rates something highly (5), Spike gives the same item a low rating (1 or 2). But when Spike gives an item a low rating (1 or 2) there's no pattern for how Giles will rate the same item. The users have a low linear correlation, as such their influence on each other will be low despite the fact Giles might be a good negative predictor for Spike.
The correlation between the two users is near zero, so they would have little influence on each other in the recommendation process. It would though be conceivable to interpret positive ratings of Giles as perfect negatives for Spike. This fact, and many similar such cases, is however completely ignored with the correlation approach as it uses a model that is too generalized.
- Transitivity
Since two users can only be regarded as similar if they have items that overlap, this has the effect that users with no overlap are regarded as dissimilar in the correlation approach. However, just because two users have no overlap, doesn't necessarily mean that they are not like-minded. Can such like-mindedness still be detected? Consider the following example; user A correlates with user B ; user B correlates with user C ; since user A has no items in common with user B the two do not correlate. But one thing they do have in common is their similarity with user B , i.e.
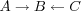 , and this information could be used to establish a similarity between users A and C .
, and this information could be used to establish a similarity between users A and C .
Different ways of improving and extending primarily the correlation based similarity measures have been developed, some of the more widely known and used are the ones proposed by Breese [breese98empirical] and Herlocker [herlocker00understanding] . Breese suggests three different extensions, default voting , inverse user frequency and case amplification . Herlocker suggests the use of significance weighting .
- Default voting
Since the reliability of the correlation between two users increases with the number of items that are used for calculating the correlation, few co-rated items means that the reliability of the similarity is questionable. Instead of only using co-rated items, Breese suggests that the union over all items that two user have rated should be used. For each item in the union where one of the two users has a missing rating, a default rating is inserted. Breese suggests that the default value should be a neutral rating or a somewhat negative preference for the unrated item. It is important to realize that the basic idea of default voting only applies to the union of items rated by both users in question. However, they also suggest that a default value can be added to some additional items that neither one of the two user have rated but that they might have in common.
- Inverse user frequency
The extension is based on the idea that universally liked items are not as useful in capturing similarity as less common ones. Inverse user frequency for an item is calculated by taking the logarithm of the ratio between the total number of users and how many that have rated the item. This is analogous to the inverse document frequency typically used in information retrieval to reduce influence of common words when calculating document vector similarity. The ratings for each item is then multiplied by their calculated inverse user frequency when calculating similarity between users's rating vectors (this would not be suitable for correlation based approaches).
- Case amplification
Refers to a transform applied to the similarity. Positive similarities will be emphasized while negative will be punished. Breese uses a formula where positive similarities are left unmodified, and negative similarities are modified to lie closer to zero.
- Significance weighting
A method that devalues similarities that are based on too few co-rated items. It is based on the observation made by Herlocker that users that have few items in common but are highly correlated, usually turns out to be terrible predictors for each other. His experiments show that a minimum of 50 co-rated items is typically required for producing more accurate predictions, imposing a higher value on the minimum number of co-rated items doesn't have any significant effect on the accuracy. If two users have 50 or more items in common, their similarity is left unmodified, but if they have less than 50 co-rated items, the similarity is multiplied with the number of co-rated items divide by 50.
In particular significance weighting is also a useful extension for cosine based similarity measures. In [sarwar01itembased] the adjusted cosine similarity measure and significance weighting is used to determine item similarities based on user ratings, they report better results when using the adjusted cosine than when using the person correlation coefficient as a similarity measure.
Pearson's correlation coefficient
[resnick94grouplens] suggested (by use of an example) the usage of the Pearson correlation coefficient as a similarity measure between users item ratings.
By studying how users ratings are distributed in a scatter plot it is determined whether a positive or negative linear correlation exists between the two users ratings [scatter plots] . As with any correlation based similarity measure only co-rated items can be considered (unless an extension such as default voting is also used).
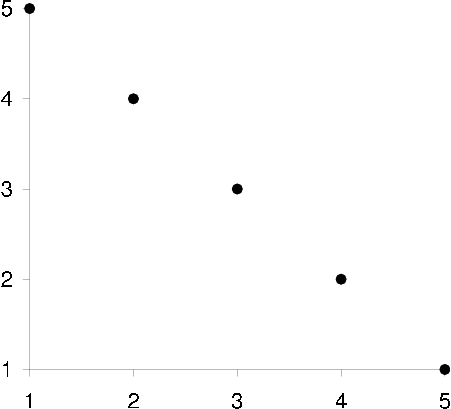
scatter plot correlation negative Correlation: -1
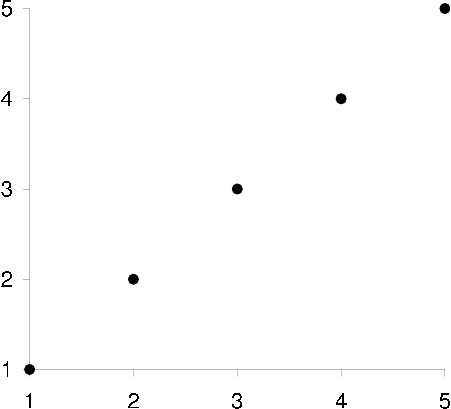
scatter plot correlation positive Correlation: +1
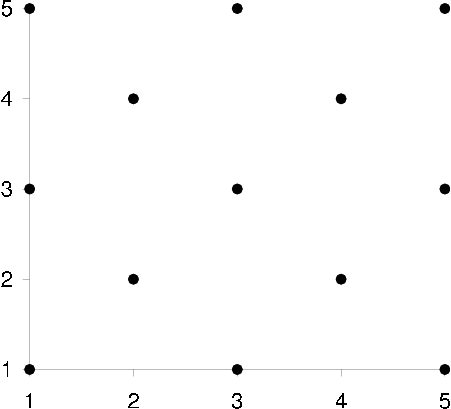
scatter plot correlation zero Correlation: 0
scatter plots Scatter plots showing two users u (x-axis) and n (y-axis) correlation when assigning ratings on a discrete rating scale  to items. A -1 correlation can be interpreted as whenever user u rates something high user n rates it low, or whenever u rates something low n rates it high. A +1 correlation can be interpreted as whenever user u rates something high user n rates it high, or whenever u rates something low n rates it low. A 0 correlation simply means that whenever u rates something low, n might rate it low too or just as likely rate it high, no linear relationship exists in the scatter plot.
to items. A -1 correlation can be interpreted as whenever user u rates something high user n rates it low, or whenever u rates something low n rates it high. A +1 correlation can be interpreted as whenever user u rates something high user n rates it high, or whenever u rates something low n rates it low. A 0 correlation simply means that whenever u rates something low, n might rate it low too or just as likely rate it high, no linear relationship exists in the scatter plot.
The correlation between two users u and n is calculated using the two user's respective row in the user item rating matrix (as previously described), but ignoring columns for items both users haven't rated. Since it is practical to not have to deal with missing values in the matrix, we will adopt a variation of the user item rating matrix model (in the next chapter a formal definition of this model will be given) which associates a set of ratings with each user. Let; ru, i denote the r ating on item i by user u ; ur denote the set of ratings given by user u . The similarity between users u and n can then be defined by their Pearson correlation as follows:
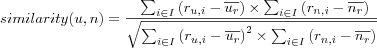
where I is the set of co-rated items, i.e. 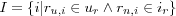 .
.
Note that the mean ratings 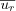 and
and 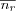 for each user should be calculated over the set of co-rated items since the correlation formula only deals with co-rated items. Variations of the formula exist, particularly one form that does not require the calculation of user means is often used. The similarities defined in this manner will lie in the interval [-1, 1] where similarities near -1 mean negative correlation and similarities near +1 mean positive correlation. Values around zero indicate that no linear correlation existed between the two users, this doesn't necessarily mean the two users have dissimilar taste, however in lack of further analysis we must assume the users are dissimilar.
for each user should be calculated over the set of co-rated items since the correlation formula only deals with co-rated items. Variations of the formula exist, particularly one form that does not require the calculation of user means is often used. The similarities defined in this manner will lie in the interval [-1, 1] where similarities near -1 mean negative correlation and similarities near +1 mean positive correlation. Values around zero indicate that no linear correlation existed between the two users, this doesn't necessarily mean the two users have dissimilar taste, however in lack of further analysis we must assume the users are dissimilar.
While the application of the Pearson correlation coefficient has been in terms of determining similarity between two users, a similar reasoning applies to finding the similary between two items. The correlation between two items is calculated using the two items's respective column in the user item rating matrix, but ignoring rows for users that haven't rated both items. To denote the set of ratings given to an item i the notation ir is used. The similarity between items i and j can the be defined by their Pearson correlation as follows:
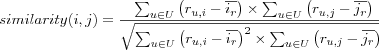
where U is the set of co-rated items, i.e. 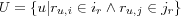 .
.
As can be seen the notation is the same with users substitued for items.
Cosine angle
In the user rating matrix terminology we can can view each user's row in the matrix as a rating vector, and use the cosine angle as a similarity measure between two users rating vectors. The cosine angle is measured in an N -dimensional space where N is the number of co-rated items between the two users.
Using the previously adopted terminology the similarity between users u and n can be defined by the cosine angle between their ratings vectors as follows:
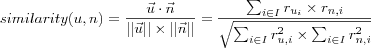
The similarities defined in this manner will lie in the interval [0, 1] , where zero means no similarity and one strong similarity.
Adjusted Cosine
When finding the similarity between two items based on users ratings on the items, [sarwar01itembased] found that using an adjusted version of the cosine angle when calculating similarities produced better results (the resulting predictions relying on the calculated similarities were better in terms of some evaluation metric) than using the cosine angle and the person correlation coefficient in the similarity calculation.
The similarity calculation based on adjusted cosine unlike basic cosine takes into consideration that users use different personal rating scales. The similarity between items i and n is now defined as:
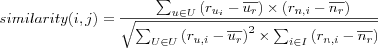
Mean squared difference
Used most notably in the Ringo system. Let |I| denote the number of co-rated items for user u and n . The similarity between users u and n is defined as:
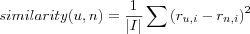
Recommendations
Equally prevalent in CF research as similarity measures, is research into how to use the similarities to make actual recommendations. Two distinct types of recommendations are considered to exist, predictions and ranking lists (top N lists). A prediction is a value indicating to a user some kind of preference for an item, while a ranking list consists items the user will like the most sorted in descending order of preference, typically only the top N items in the ranking list are shown.
Prediction algorithms
A prediction is a numerical value pu, i that express the preference (interest, "how much something will be liked") of item i for a user u . The preference is usually encoded as a numeric value within some discrete or continuous scale, i.e. [1, 5] where 1 expresses dislike and 5 a strong liking. Several different prediction algorithms have been proposed in the literature. The most commonly used is [weighted deviation from mean] , commonly known as weighted deviation from mean , which was first proposed in the GroupLens System [resnick94grouplens] .
Prediction algorithms rely on a set of neighbors N that consists of users that for simplicity in this discussion will be assumed to have rated the active item i . Three common ways of computing predictions are then:
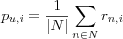
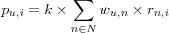
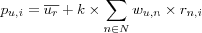
The constant k , sometimes called the "normalizing constant" is usually taken to be:
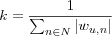
The normalizing constant doesn't cause the predictions to lie within the original rating scale the predictors rated items on, however it will make them lie "close enough". Predictions can be put into the original rating scale by clamping values (e.g. clamp all prediction above 5 to 5). In a sense the predictions are relative each other, a high predicted value indicates a stronger preference than a lower predicted value, however since predictions are often viewed "on their own" it does become necessary to clamp the predictions to a scale the user can understand.
Note the usage of wu, n where w stands for weight. The first prediction algorithm uses no such weight, it simply calculates the whole population's average rating for the active item i . The weight is introduced in the second prediction algorithm to discern between levels of user similarity, this weight is the similarity between the active user and each neighbor contributing to the prediction, which in this case means all users in the population that have rated the item. (Weights are always taken as some form of similarity between users, the term weight stems from the recommender systems histoy in information retrieval and filtering and will not be used beyond this chapter, instead the more obvious term similarity will be used.)
The first prediction algorithm [average rating] expresses the simplest case, the predicted value is just the average value for that item given by all users (because of this the name Item mean is sometimes used to refer to this prediction algorithm). This algorithm is often used as a baseline predictor when new prediction algorithms are tested.
The most common aggregation formula used is [weighted average rating] (which can be refered to as the Weighted average rating prediction algorithm), it weighs all user with respect to its similarity to the active user. The purpose of the weighting is to ensure that like-minded users for the active user will have more to say in the final prediction, this algorithm was used in for example the Ringo system [shardanand95social] .
However, it has been found that users use different rating scales when rating items, e.g. some users will be very restrictive about giving items top ratings, while other users may be more generous or have widly different definitions of what a top rating means and and rate many items they like with top ratings (perhaps two users have the opinions "great movie, I give it a two" and "terrible movie, I give it a two" about the same movie, which isn't unusual as the authors can testify). This means that the rating distribution between users will be skewed. Letting a user that rates many movies with the top rating predict for a user that is very restrictive about top grades may have a negative effect on prediction quality. In order to neutralize the negative effect of the skewed rating scales, [weighted deviation from mean] was introduced. The very basic idea is to start out with the active users mean rating, and then look at how the active user's neighbors deviate from their mean rating (because of this the prediction algorithm is often referd to as Weighted deviation from mean ). If the neighbors do not deviate from their mean rating, then neither should the active user. This prediction algorithm was used first in the GroupLens System [resnick94grouplens] .
Common prediction algorithms used by item based CF have similarities with the previously presented prediction algorithms, however with some important differences. The neighborhood set N consists of items similar to the active item i . For discussion it will be assumed that N consists of all items similar to the active item.
A algorithm in the item based case that is similar to [average rating] would simply take the active users average rating on all items he has rated. However as that makes little sense, the items' degree of similarity is also accounted for.
A common algorithm for making predictions in item based CF is [weighted sum] (often referd to as Weighted sum ) (with e.g. 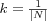 ).
).
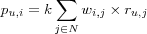
Ranking algorithms
A ranking list, or more commonly a top N list since the ranking list typically consists of the N items (out of all available in the dataset) that the active user will like the most sorted in descending order of preference. Top N lists can be created both by simply sorting predictions, or by using algorithms specifically designed for top N list generation. Any recommendation technique making predictions can also sort the predictions to generate top N lists. Thus the following methods for generating top N lists are usually created when the underlying data is not ratings, rather transaction data, e.g. information on what items a user has purchased. However, there is nothing to prevent using rating, however it will be necessary for some parts of the algorithm to reduce the rating data to unary data, this means loosing information which might lead to worse results had predictions been sorted.
Two ways of producing top N ranking lists, when the underlying data is transaction data, are given in [karypis01evaluation] and are outlined below.
- Frequent item recommendations
This method creates a top N ranking list by first creating a set of items consisting of all items neighbors of the active user has purchased . Items that the active user has purchased are excluded from the set. The frequency of each item in the set is counted, i.e. it is counted how many of the neighbors purchased each item. The items are then sorted in descending order of frequency. The N most frequent items are then presented to the active user as a top N list.
- Similar item recommendations
This method creates a top N list by first creating a candidate set of the k most similar items for each of the items in the active users profile. The set consists only of distinct items and items already purchased by the active user are removed. For each item in the candidate set, its similarity to each of the items in the active users profile is computed and summed up. The N items in the candidate set are then sorted with respect to their summed similarity to the active users profile. The N items with the highest summed similarity are then presented to the active user as a top N list.
In [karypis04itembased] an interesting variation on their similar item recommendations method is proposed. Instead of only finding the k most similar items for each item in the active users profile, the k most similar items to all possible sets of items in the active user's profile are found. For example, suppose the active user has three items i1 , i2 and i3 in this profile, then the candidate set should include the k most similar items for not only items i1 , i2 and i3 , but also for the sets
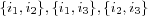 and
and 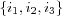 . This requires a similarity measure that is able to determine similarity between one item and a set of items. They claim that this approach will discover items that can be of potential interest to the active user that otherwise wouldn't be found, i.e. the k most similar items to e.g. the set
. This requires a similarity measure that is able to determine similarity between one item and a set of items. They claim that this approach will discover items that can be of potential interest to the active user that otherwise wouldn't be found, i.e. the k most similar items to e.g. the set 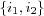 might include items that are not in either of the individual items list of k most similar items. Techniques implementing this method of generating top N list require very large models of the k most similar items to be build, to reduce model size only item sets that occur frequently among users can be used. The notation frequent item sets is used by the data mining community in connection with association rules as defined in [agrawal93mining] .
might include items that are not in either of the individual items list of k most similar items. Techniques implementing this method of generating top N list require very large models of the k most similar items to be build, to reduce model size only item sets that occur frequently among users can be used. The notation frequent item sets is used by the data mining community in connection with association rules as defined in [agrawal93mining] .
Content Based Filtering
Information filtering and content based filtering refers to the same paradigm, filtering items by their content. However information filtering is most often used in connection with text documents, while content based filtering allows for a wider definition of content. Pure content based filtering, as defined in [balabanovic97fab] , is when recommendations are made for a user based only on a profile built up by analyzing the content of items that the user has rated or otherwise shown interest in. We will be using the term content based filtering since we will not constrain our self to text documents only, that is, we will use any content that after some preprocessing can be used in the filtering process. From the definition we can identify two important steps in content based filtering, the need for both a technique to represent the items and for a technique to create the user profiles.
Many of the techniques that have been developed and used in text retrieval and text filtering have been adopted by the content based approach [oard97stateoftheart] . One of the more popular techniques is the vector space model and especially the tf-idf weighting scheme for representing the content of the text documents. Popular approaches for creating user profiles are techniques found in the machine learning field. One such technique is the use of a classification algorithm that can learn a user profile that it can use to distinguish between items that are liked and disliked by the user.
So not surprisingly, recommender systems that use the content based approach are often found in domains where the content has some similarity to plain text documents. For example Syskill & Webert [pazzani96syskill] is a content based recommender system for webpages. Users rate webpages on a three point scale, the system can then recommend new WebPages or create a search query for the user to be used in a search engine. Users of the system are presented with an index page that links to several manually created topic webpages that contains hundreds of links to pages within that topic. The system creates user profiles for each topic rather than user profiles for all topics combined. Based on the user profiles, some of the links on the topic pages will be associated with a symbol (e.g. thumbs up, thumbs down, smileys, etc.) that symbolizes how much the user will like the page that is linked to.
In the Syskill & Webert recommender system each webpage is represented as a boolean feature vector consisting of the k most informative words for the topic it belongs to. The boolean values for each feature indicates if a word is present or absent in the web page. They chose k to be 128. Words to use as features in the feature vectors differ for each topic, but are the same for all webpage's belonging to the same topic. The words within each topic are chosen based on how much expected information gain the presence or absence of the word will give when trying to classify a webpage for a user. A learning algorithm is used to classify unrated webpage's for users, the learning algorithm analyzes the content of all the pages a user has rated and by this process learns the user's profile. Five different types of learning algorithms were tested by Pazzani et. al, Bayesian classifiers, nearest neighbor algorithms, decision trees, neural nets and tf-idf as described in the vector space model. The algorithms show different results over different topics, but the overall best performance is given by the Bayesian classifier. All algorithms show results that almost always beats the baseline algorithm, which is just guessing what pages a user would like.
Content based filtering systems based on item attributes differs in some aspects from keyword based systems like Syskill & Webert. Extracting product content is a straight forward process, the attributes of the product is usually well structured, such as for movies where the content consists of attributes like the movie's director, lead actress/actresses, genre etc. However, the challenge is to select only the most important attributes. The key issue here is: what defines an attribute as important? Since importance differs from product to product, no standardized ways, like for example the tf-idf weighting scheme used with text documents in the vector space model, exists for product attributes (that we are aware of). Choosing the wrong attributes can have a great impact on the performance of the recommendation technique, so the choice of attributes is usually done manually either by some domain experts or by empirical tests.
In [mellville02conentboosted] they represent the content of a movie as a set of "slots" containing attributes of the following type: movie title, director, cast, genre, plot summary, plot keywords, user comments, external reviews, newsgroup reviews and awards. A movie will in this case be represented as a vector of bags of words . A naive Bayesian classifier is then used to create user profiles. They report almost equal performance between their implementation of a user based collaborative filtering technique and the content based filtering technique.
A way of making movie recommendations with a minimum of knowledge about the users is described in [fleischman03recommendations] . Instead of representing and learning user profiles from the users preferences about movies, the recommender system only uses one movie as a seed movie to base its recommendations on. For example, suppose the active user has a favorite movie and wants to find out if there exists any similar movies. By using the favorite movie as a seed movie, the recommender system can make some recommendations that are based on the similarity with the seed movie. They propose two different techniques for this and the only difference between them is how the content of the movies is represented. In the first technique, they only use the plot summaries of the movies and represent the movies with a binary vector, where 1 and 0 represents the presence and absence of a word respectively. The size of the vector is the same as the total size of the used vocabulary. Two movies are found similar by calculating their cosine similarity as described in the vector space model. The second technique also uses the cosine similarity for finding similar movies, but the representation of the movies is different. In this case, each movie is represented by a vector that contains the movies cosine similarities to different movie genres. Each genre is represented as a vector of keywords that are weighted by how indicative they are of the particular genre. The keywords were taken from the Internet Movie database (IMDb)(*) . Thus, the first technique recommendations movies based on how well two movie's plot summaries match, and the second one recommends movies from their shared similarity and dissimilarity to particular movie genres. Their results shows that no conclusions can be made whatsoever about the performance of their techniques, for example, they compared the top five recommendations from their techniques against the output from IMDb on one particular movie and none of them recommended the same movies.
Vector Space Model
The vector space model is described in [salton83introduction] as a vector matching operation for retrieving documents from a large text collection. The user formulates a search query consisting of words that best describes his information need and this query is then matched against all documents in the text collection. The matching operation uses a similarity formula to determine which documents best matches the search query and then retrieves those documents for the user.
In this model, a document (and a search query) is represented by a vector of weighted keywords (terms) extracted from the documents [salton88termweighting] . The model is also popularly called the bag of words representation since the words are stored in a unordered structure that does not retain any term relation. For example, terms appearing together in a document can have some special meaning, but that will be lost by this kind of representation. The weights represent the importance of the keywords in the document as well as in the entire collection of documents. Since each document vector is represented in a vector space that is spanned by the number of terms, this model can be viewed as a term document matrix [term document matrix] , where rows are documents and the columns are all (or some of) the terms that appear in the document collection.
| t1 | t2 | ... | tj | |
| d1 | w11 | w12 | ... | w1j |
| d2 | w21 | w22 | ... | w2j |
| ... | ... | ... | ... | ... |
| di | wi1 | wi2 | ... | wij |
term document matrix Term document matrix. The rows represent documents and the columns terms that appear in the document collection, but not necessarily in all documents. The cells contains weights indicating the importance of each term in each document.
If we use wi, j to denote the weight for term j in document i , the document vector can be expressed as:
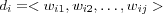
This model has been used for a long time as a basis for successful algorithms for ranking, filtering and clustering documents, see for example [baeza-yates99modern] .
Three factors that must be considered when calculating the weights are term frequency , inverse document frequency and normalization . After all the weights have been calculated, similarity between two documents d1 and d2 can be calculated using for example the cosine angle:
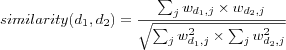
The term frequency is just a count of how many times a term occurs in a document. If a term occurs many times in a document, then it is considered important for that particular document. The term frequency f for term j in document i , i.e. the number of occurrences of term j in document i , is denoted as fi, j . This is sometimes referred to as the terms local frequency.
The inverse document frequency (IDF) identifies terms that occurs only in a few documents. Such terms are considered to be of more importance than terms that are prevalent in the whole document collection. Terms occurring in the whole document collection make it hard to distinguish between documents and if used causes all documents to be retrieved which naturally affects the search precision. The IDF factor is usually referred to as the terms global frequency. The IDF factor for a term is inversely proportional to the number of documents that the term occurs in, since when the document frequency for a term increases, its importance decreases. The frequency f for term j in document d is denoted as dfj and the inverse document frequency for term k in document d is denoted as idfj . The inverse document frequency ifj is inversely proportional to the document frequency dfj , i.e.:
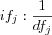
and varies with the document frequency dfj . The idfj for a term j is usually taken as the logarithm of the ratio between the total number of documents D and the document frequency, i.e.:
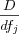
The logarithm (which can be taken to any convenient base) is just there for smoothing out large weight values. Thus we get:
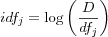
The term frequency fi, j and the inverse document frequency idfj can be combined as 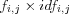 to obtain a weight that accounts both for terms occurrences within a document and within the whole document collection. However, it is necessary to perform some normalization in order to avoid problems related to keyword spamming and bias towards longer document. Two types of normalization that is suggested is normalized term frequencies and normalized document lengths .
to obtain a weight that accounts both for terms occurrences within a document and within the whole document collection. However, it is necessary to perform some normalization in order to avoid problems related to keyword spamming and bias towards longer document. Two types of normalization that is suggested is normalized term frequencies and normalized document lengths .
Since higher term frequencies fi, j results in a larger weight value than for terms with a lesser frequency models are vulnerable to keyword spamming, i.e. a technique where terms are intentionally repeated in a document for the purpose of generating larger weight values and by that way improving the chances of the document being retrieved. One way to avoid this is to calculate the normalized term frequency . The normalized term frequency of term j in document i is denoted tfi, j and is usually calculated by dividing the frequency of the term j with the maximum term frequency in document i denoted max(fi) , i.e.:
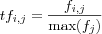
Normalized document lengths are used since longer documents usually use the same term more often, resulting in larger term frequency factors, and using more different terms as opposite to shorter documents. This means that longer documents will have some advantages over shorter ones when it comes to calculating the similarity between documents. To compensate for this cosine normalization can be used as a way of imposing penalty on longer documents, it is computed by dividing every document vector by its Euclidian length. The Euclidian length of a document i is defined as:
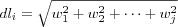
Terms that should receive the highest weight are those that have high term frequency and low overall document collection frequencies. Salton [salton88termweighting] refers to this property as term discrimination since this suggest that the best terms are those that can be used to distinguish certain documents from the remainder of the collection. This is achieved by multiplying the normalized term frequency with its inverse document frequency 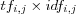 , and then normalizing it to achieve the final weight for the term j in document i :
, and then normalizing it to achieve the final weight for the term j in document i :
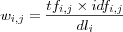
Hybrid Filters
Both collaborative filtering and content based filtering have their strengths and weaknesses, hybrid filters are an attempt to combine the strengths of both techniques in order to minimize their respective weaknesses. There are many examples of recommender systems based on hybrid filters.
- FAB
A content based collaborative filtering system for webpage's [balabanovic97fab] . In FAB webpage's are represented by the words that receives the highest tf-idf weight and the user profiles are represented by an tf-idf vector that is the average of the webpage's that are highly rated by the user. The user can then receive recommendations from similar users using the collaborative approach or by direct comparison between a webpage and a user's profile. Their results show that the FAB system makes better recommendations compared to recommendations that are randomly selected, human selected "cool sites of the day" or pages best matching an average of all user profiles in the system.
- Syskill & Webert
Pazzini [pazzani99framework] extended the content based technique that was used in his Syskill & Webert [pazzani96syskill] recommender system with collaborative filtering techniques. He refers to this new technique as collaboration via content . Webpage's are represented by the 128 most informative keywords for the class they belong to. A content based approach different from the one presented in [pazzani96syskill] is used both on its own and in combination with a collaborative filtering technique. In the content based approach a user profile is learned by first applying an algorithm that assigns weight values to each informative word in a webpage a user has rated. Weights are initially set to 1, the weight values for each webpage are then summed up and if the sum is above a threshold value and the user liked the webpage, the weights are doubled, otherwise they are divided by two. Training stops after 10 iterations over all pages or when each rated webpage is correctly classified (i.e. weights for words on all positively rated pages sum over the threshold, and weights for words on all negatively rated pages have a sum under the threshold). Webpage's are then recommended by applying the user's weight values on the words that occurs in each webpage and summing up the total weight for each webpage, the webpage's with the highest sum are recommended to the user. In the collaboration via content technique the content based user profiles, consisting of the user's word weights, are used instead of user profiles consisting of ratings, in the same manner as in standard collaborative filtering. Their experimental results show that when users have very few webpage's in common, collaboration via content has a better precision than standard collaborative filtering. But as soon as users get more and more webpage's in common, collaborative filtering performs almost equally well. Precision was measured based on the top three webpage's that was recommended to a user.
- P-TANGO
[claypool99combining] is a recommender system for news articles from an online newspaper that uses both the content based approach and the collaborative approach in the recommendation process. It's not a hybrid system in the sense that the two approaches depend on each other, instead they are implemented as two separate modules that are independent of each other. The recommendations from the two approaches are instead weighted and combined to form a final recommendation. One advantages over hybrid systems where both approaches are tightly coupled and deeply dependent on each other, is that the system can choose which approach should have more confidence during different circumstances. For example, when few people have accessed a news article, the content based recommendation is weighted higher but as soon as more and more people is showing interest in the article, the recommendations based on the collaborative approach take over. Also, improvements of the system is easier, since whenever someone comes up with a new and improved way of making either collaborative or content based recommendations, these are easily incorporated into the system. The user profiles in the content based approach consists of keywords that are matched against item profiles that consists of extracted words from news articles. The keywords in the user profiles are either taken from articles the users have rated highly or are keywords the users have marked as important. Their experimental results show that the combined recommendations are a bit more accurate than either of the separate ones.
- Rule based using Ripper
In [basu98recommendation] they treated the task of recommending movies to users as a classification problem. They saw the recommendation process as the problem of learning a function
 that takes as input a user and a movie and produces an output that tells whether the user will like or dislike the movie. For this task, they chose to use an inductive learning system called Ripper. Ripper is able to learn rules from set-valued attributes, in this case by taking as input a tuple
that takes as input a user and a movie and produces an output that tells whether the user will like or dislike the movie. For this task, they chose to use an inductive learning system called Ripper. Ripper is able to learn rules from set-valued attributes, in this case by taking as input a tuple 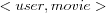 consisting of two set-valued attributes user and movie. They created tuples consisting of what they call collaborative features (user's ratings on movies) and content features (information available on movies, they used over 30 different attributes). Using for example collaborative features the <user, movie> tuple would contain for the user attribute which movies the user likes, and for the movie attribute which users that likes the movie (e.g.
consisting of two set-valued attributes user and movie. They created tuples consisting of what they call collaborative features (user's ratings on movies) and content features (information available on movies, they used over 30 different attributes). Using for example collaborative features the <user, movie> tuple would contain for the user attribute which movies the user likes, and for the movie attribute which users that likes the movie (e.g. 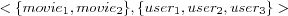 where movie1 and movie2 are two movies liked by the user in question, and user1 , user2 and user3 are three other users that like the movie in question). They also used what they call hybrid features, e.g. a movie was represented using users that like a particular genre. Each such
where movie1 and movie2 are two movies liked by the user in question, and user1 , user2 and user3 are three other users that like the movie in question). They also used what they call hybrid features, e.g. a movie was represented using users that like a particular genre. Each such 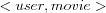 tuple is then labeled by whether or not the movie was liked by the user. Given such tuples the Ripper can be trained to create rules for every user, which can be used in the recommendation process. Example of an interpretation of a rule for a user that like action movies can be " if action is present among movies that the user likes then predict user likes movie" . They report that their approach performs reasonably well compared to the collaborative approach on the same data. However, this is only achieved with the combination of a great deal of manual work in selecting and refining the attributes and at a low level of recall.
tuple is then labeled by whether or not the movie was liked by the user. Given such tuples the Ripper can be trained to create rules for every user, which can be used in the recommendation process. Example of an interpretation of a rule for a user that like action movies can be " if action is present among movies that the user likes then predict user likes movie" . They report that their approach performs reasonably well compared to the collaborative approach on the same data. However, this is only achieved with the combination of a great deal of manual work in selecting and refining the attributes and at a low level of recall.- CF with content based filterbots
Sarwar et. al uses in [sarwar98using] what they refer to as filterbots, software agents whose only purpose is to give content based ratings on new items that arrives into the system. Since the filterbots are used as recommenders for those users that correlate with them, new items will be available for recommendation much faster then if they had to wait for real users to come along and rate them. They tested their filterbots in the GroupLens system that recommends articles from a Usenet news server. One of the filterbots they implemented was a SpellCheckerBot, whose sole purpose was to run a spell checking algorithm on every new article that arrived to the Usenet news server. The final rating on the article was then decided based on the number of misspelled words. Other filterbots that they tried based their ratings on the length of the article and number of quotes in the articles. They report that a simple filterbot like the spell checker can improve both the coverage (number of items available for recommendation among all items) and the accuracy of the given recommendations. Their results however show that filterbots are sensitive to which domain they operate over, e.g. some did well in newsgroups about humor but some did not etc.
- Content-boosted CF
In [mellville02conentboosted] they implement two hybrid systems, the first one combined the outcome from a pure content based filtering technique with the outcome from a user based collaborative filtering technique by taking the average of the ratings that are generated. Their other system is called content-boosted collaborative filtering (CBCF). This system first creates pseudo user-ratings vectors for every user by letting a content based filter (as previously described) predict ratings for every unrated item. These pseudo user-ratings vectors are then put together to give a dense pseudo-user ratings matrix. Collaborative filtering is then performed by the use of this matrix. Similarity between two users are calculated based on the pseudo ratings matrix, in the prediction process two additional weights are added; the calculated accuracy of the pseudo user-ratings vector for the active user and a self-weight that can give extra importance to the active users pseudo self, since he is used as a neighbor. Their results shows that the CBCF performs best, followed by pure CF, combined CF and CB and last pure CB. Although, the difference between the CBCF and the pure CB is very small.
- Combining attribute and rating similarity
Two different recommendation techniques for movies is presented in [jin99using] that both use a combination of item similarity in their implementation of a item based collaborative filtering technique. Similarity between two movies is first calculated based on ratings given to them by users and then based on their content (they refer to content similarity as semantic similarity). These two similarities are then combined into one single similarity score. Rating similarity between two movies is calculated using adjusted cosine. Content similarity is calculated as a linear combination of the similarity between the movies attribute. The content of a movie includes the following attributes; title, year, director, genre, cast, MPAA rating and plot summary. After preprocessing of the content data, the movie is represented as a vector of attributes, where each attribute is represented in some suitable way, e.g. as a bag-of-words in the case of plot summary. Content similarity between two movies, denoted ConSim(i,j) where i and j are two movies, are calculated using their terminology as
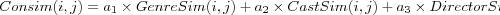 where
where  are predefined parameters that are used as weights. Each attribute similarity is calculated with some suitable method. The final similarity score between two items i and j is then calculated as
are predefined parameters that are used as weights. Each attribute similarity is calculated with some suitable method. The final similarity score between two items i and j is then calculated as  where RateSim(i, j) denotes the rating similarity between two movies and α is a predefined parameter used as a weight. Note that with α = 0 this becomes a pure item based collaborative filtering technique. The combined similarity score is used as a weight in the weighted sum formula for producing predictions for the active user (as previously described). This is also how their first technique works. Their second technique, differs in that they first uses the combined similarity score to predict ratings for unrated items to decrease the sparsity in the rating matrix. For each unrated item they find all its similar items that are above some predefined similarity threshold and uses the weighted sum of these similar items ratings as the estimated rating for the unrated item. Unlike [mellville02conentboosted] they don't create a fully dense matrix, they only choose to rate some of the unrated items. This new matrix is then used as in their first technique. Their result shows that there is no significant difference in using a combination of rating and content similarity from using only rating or semantic similarity. On the other hand, this means that content similarity can be used in cases when there are to few ratings for calculation of rating similarity. (Note: they do claim that their techniques improve accuracy of the predictions, but that claim comes from observations of the third and fourth (!) decimal in their calculations of the mean absolute error. You just cant take such a claim seriously, the mean absolute error is explained in detail in the next chapter as well as a discussion given on why such differences in the thrid and foruth decmial does not matter to the end user.)
where RateSim(i, j) denotes the rating similarity between two movies and α is a predefined parameter used as a weight. Note that with α = 0 this becomes a pure item based collaborative filtering technique. The combined similarity score is used as a weight in the weighted sum formula for producing predictions for the active user (as previously described). This is also how their first technique works. Their second technique, differs in that they first uses the combined similarity score to predict ratings for unrated items to decrease the sparsity in the rating matrix. For each unrated item they find all its similar items that are above some predefined similarity threshold and uses the weighted sum of these similar items ratings as the estimated rating for the unrated item. Unlike [mellville02conentboosted] they don't create a fully dense matrix, they only choose to rate some of the unrated items. This new matrix is then used as in their first technique. Their result shows that there is no significant difference in using a combination of rating and content similarity from using only rating or semantic similarity. On the other hand, this means that content similarity can be used in cases when there are to few ratings for calculation of rating similarity. (Note: they do claim that their techniques improve accuracy of the predictions, but that claim comes from observations of the third and fourth (!) decimal in their calculations of the mean absolute error. You just cant take such a claim seriously, the mean absolute error is explained in detail in the next chapter as well as a discussion given on why such differences in the thrid and foruth decmial does not matter to the end user.)
Unfortunately, a direct comparison of the results between theses techniques is nor feasible since they all uses different datasets, different sizes of the datasets, different evaluation protocols etc. The need of a standardization for evaluation of recommendation techniques is a major issue and will be discussed further in the next chapter.
Recommender Systems
The environment for a information retrieval system is static in the sense that the available information changes slowly but user needs change frequently. In contrast, information filtering systems are dynamic as the information changes very often (typically there are "streams of information" that need filtering), but user needs are a bit more static [belkin92information] . It seems therefore natural to build a system that support both of these approaches for handling massive amounts of information, and one such type of systems are recommender systems.
The environment for a recommender system is usually of a highly dynamic nature, both from the information viewpoint and the user viewpoint. Users and items are added and removed often and user's preferences and needs change over time. Additionally the way users interact with the system itself is of a dynamic nature, e.g. searching, browsing, commenting, rating, etc. The domain that a recommender system operates over is usually very high dimensional and sparse, i.e. items can be of magnitudes thousands to millions of which only a very few are known by each individual user.
One of the first articles that uses the term recommender system is written by Resnick and Varian [resnick97recommender] , the term was there used to define a system that uses collaborative filtering to make recommendations to users:
"In a typical recommender system people provide recommendations as inputs, which the system then aggregates and directs to appropriate recipients"
The term recommender systems has since then become synonymous with any system that produces recommendations, not only systems based on collaborative filtering. [schafer01ecommerce] gives a taxonomy from a user perspective for different types of recommender systems used by e-commerce sites, [burke02hybrid] identifies and classifies different hybrid recommender system.
However, as early as 1990 the term "recommender" occurs in the paper "An Algebra for Recommendations: Using Reader Data as a Basis for Measuring Document Proximity" [karlgren90algebra] by Karlgren at Swedish Institute of Computer Science(SICS) where he used the term recommender when he tried to define what he referred to as an "recommender algebra" based on a collaborative approach and later, his paper "Newsgroup Clustering Based On User Behavior - A Recommendation Algebra" [karlgren94newsgroup] was used as a reference in [resnick94grouplens] , which is one of the earliest recommender systems based on the collaborative approach .
Recommender systems in e-commerce
In every domain of items, there are some items that directly appeal to a broad audience, or by some marketing strategy make it to the top charts. This has the effect that niche items or items without financial backup for marketing have trouble reaching out to the broader public. This creates a market where popularity and strong economic interests dictate what the broad audience should like and buy. The Web and in particular recommender systems have changed this, at least to some degree. Recommender systems in e-commerce are not only a way of providing better customer services by giving personalized suggestions and customized ways of searching and browsing the product database, but it also has the effect of increasing sales on obscure items, items that for some reason didn't find a broad audience when they was released. Items without large financial backup and without an immediate broad appeal thus no longer automatically remain unnoticed by the larger public, and as such get a chance to reach their public, even though it may still be niche items. A theory that describes this is called the long tail, where the term tail refers to obscure items that for some reason can be found in context with more popular items, called the heads. This theory was formulated and presented in an article with the same name in the Wired magazine [anderson04wired] . The effect was observed when a fifteen year old book about mountain climbing suddenly reach the top of New York Times bestseller list and stayed there for 14 weeks. What had happened was that Amazon.com's book recommender system had noticed a buying pattern among its customers and suggested that people who liked a newly published book about the same subject would also like this book. People followed up on the recommendation, and the fifteen year old book started to sell like never before. The combination of infinite shelf space with real-time information about buying trends and public opinion resulted in a rising demand for an obscure book. This is something that traditional retailers can't offer and that's why recommender systems have a bright future in the e-commerce business, because this is one of the greatest strengths with recommender systems, the ability to recommend interesting items that most users otherwise might not have found out about.
Several of the early on developed recommender systems found their way into the commercial market. GroupLens founded NetPerception Inc. in 1996, The people behind Ringo founded Agent Inc. in 1995, later changed the name to Firefly and was bought by Microsoft in 1998. One of the biggest e-commerce sites on the WWW, Amazon.com, started to use recommender systems as a part of their site in 1998 [linden03amazon] . Nowadays, almost every e-commerce site use some kind of recommender system, from simple ones that only recommend items according to statistics to complex ones like Amazon.com that uses several different approaches and recommendation techniques.
Trust in recommender systems
The success of e-commerce recommender systems depend a lot of trust being achieved from both the user side as well as from the seller's side. A user must feel confident that the recommendations are trustworthy and not just another trick from the seller's side to increase sales without regards to the customers interests, and the seller must trust that the information gathered from the users truly reflects their opinion on the items. In the paper [lam04shilling] this issue is investigated in the movie domain, where the observation had been made that the average rating for new movies was higher than the average rating for the same movie after a significant amount of people had rated it. The author hypothesized that this could be the effect of a so-called shilling attack, i.e. an item is initially given an unfair amount of high ratings (by e.g. the seller) in the hopes that more people will notice it. However, no clear evidence could be found that supported this hypothesis, one explanation they gave was that new movies tend to be initially highly rated because the people who first know about it are users who already like it and are a big fans of it. But one can argue that this is a possibility that must been taken seriously and thought off in the design of a recommender system.
Similarly, rumors had been circulating that a certain recommender systems had been manipulated to always include recommendations for items that otherwise collected dust on the shelves. If a recommender system is caught performing such types of false and greedy recommendations, it will certainly loose all its achieved trust among its users and when the trust is gone among the users, it's gone for a long time.
The focus on understanding and trusting recommender system is something that has gained a lot of research interest the last couple of years, the GroupLens team for example hosted a workshop in conjunction with the 2005 year's Intelligent User Interfaces Conference , where trust was one of the main topics. Some researchers have tried to implement implicit trust into a recommender system on the algorithmic level, hoping this would result in that the explicit trust for the recommendations would increase as a direct result of more accurate recommendations, one such approach is described in the paper Trust in Recommender Systems [odonovan05trust] where they uses the collaborative approach for recommendations. To implement trust, the systems keeps track of scores of how well every user is able to recommend items to other users, for every recommendation that match the active users real opinion of an item, the score goes up for the user and for every time there is a mismatch, the score goes down for the user. The idea is that this should reflect real life trust, i.e. if you know someone that is good on recommending movies to you, then you have more trust in this person's recommendations compared to others. They show some significant improvements compared to the user based collaborative filtering approach as described in GroupLens: an open architecture for collaborative filtering of netnews [resnick94grouplens] but the main drawback is the calculation of the trust score. The only way of calculating it, is by letting users recommend items that other user already have an opinion about and then checking who was successful and who was not, this must be done all the time and would probably have an impact on the performance of the system.
In the paper Trust-aware collaborative filtering for recommender systems [massa04trust] they propose that recommender systems should be extended with what they refer to as trust-awareness: it should be possible to base recommendations only on ratings given by users that the active user trust or are trusted by another trusted user. Trust is collected by letting users rate other users, i.e. if you in some way have interacted with another user, you can give this user a rating based on your personal experience with him. For example, suppose a user have written a review of a movie and that you, based on this review, decides to go watch it. If you experience with the movie was good, then you give the user a good rating. This can then be used in the recommendation process as an extra weight. Trust values can also be propagated through the whole community of users, i.e. if user A trust B and B trust C, then it is possible to infer something about how much A could trust C. Their results shows that by incorporating trust as weights in the recommendation process, the accuracy of the recommendations are increased, this is especially noticeable for users with very few ratings for which recommendations normally are of poor quality.
Other approaches to gain trust has been explored as well, in the paper Beyond Algorithms: An HCI Perspective on Recommender Systems [swearingen01beyond] they let user try out and judge different recommender systems in an attempt to find out which underlying factors beside the algorithm, makes a user willing to accept and explore the given recommendations. One conclusion is that an effective recommender system inspires trust in the system. The trust issue will be discussed further in Part III.
Recommendation approaches
Recommender systems takes different approaches in their effort to make recommendations for users. A recommendation approach can be seen as defining what motivates the recommendations made by a recommendation system. We distinguish between recommendation approaches and recommendation techniques , a technique is simply a very specific outline or implementation of an approach. Techniques based on the same approach will share many common features, especially in what motivates the recommendations. From our research on recommender systems, we have concluded that the following approaches represent the five most commonly used approaches.
Manual approach
This is the oldest approach, a critic reviews e.g. a movie and gives his judgement about how good or bad the movie was. Based on this the user can then decide if the movie is worth watching. Works best if the user knows the critic's preferences and thus is able to decide how much he can trust the reviewer. This is kind of a reversed personalization, the recommendations are non-personalized but the recommender himself is personalized.
Statistical approach
This approach bases its recommendations on statistical measurements such as the average rating for a item or market basket analysis ( "users who bought this movie also bought these movies" ), and popularity based recommendations such as top selling lists, top rating lists, or top box-office lists for movies etc. The recommendations are non-personalized since they are the same for every one. Due to its simplicity and efficiency this is a very popular method [schafer01ecommerce] .
Content based filtering approach
The content based approach tries to recommend items similar to the ones a user is known to like by analyzing the content of the items [balabanovic97fab] . By letting the user explicitly express his preference about items or by just assuming that items the user has bought or in some other way showed some interest in is liked by the user, the recommender system tries to match the content of those items with items that are new to the user. A user viewing a product page may receive a list of products with similar content (e.g. movies in the same genre and/or by the same director). Personal recommendations can be achieved if user profiles are maintained and updated by the recommender system. Since recommendations are based on the attributes of an item, the user can get some insight into why a particular item was recommended to him by looking at the recommended item's attributes and compare them to the items in his own profile. Thus, both trust in recommendations and transparency of recommendations can be achieved with the content based approach. A broad perspective to content is taken here which includes pure facts (e.g. actors in a movie) as well as text documents (e.g. a review or description of a movie), keywords ("tags") etc.
Collaborative filtering approach
With the collaborative approach, the recommender systems tries to recommend items to the active user with the help of other users. Unlike in the statistical approach there is a collaboration between the active user and the larger population, recommendations are thus always personalized for the active user. A classical technique based on this approach is to build a user profile from the ratings the active user has given to some items and match it against all other users to find out their similarity to the active user. This similarity is then used to weight users so the ones with high similarity, i.e. users with a similar taste as the active user, will have more influence in the recommendation process. The most similar users are often referred to as neighbors and the classical technique is sometimes referred to as a neighborhood based technique. Recommendations are given to a user on items the user hasn't yet rated by other user that have rated them. The system will either return predicted values for the unrated items or a ranked list of items which it thinks the user will like. The classical technique is based on the heuristic that users that agreed in the past will probably agree in the future [resnick94grouplens] . The user profiles are maintained and updated by the recommender system which allows for personalized recommendations. This approach can also be described as a way of automating the "word of mouth" in a community [shardanand95social] .
Hybrid approach
Since each approach has its own weaknesses and strengths, combinations of the various approaches have been made in order to use the strengths in one approach to compensate for the weaknesses in the other approach. Burke [burke02hybrid] identifies five different approaches, collaborative, content-based, demographic, utility-based and knowledge-based. Since the demographic approach deals with finding users with a similar demographic profile and to use their opinions about items to influence the recommendations for the active user, we like to think about this as a collaborative approach, similarly for the last two, utility-based and knowledge-based , we use a broader definition of content and how it can be used and therefore classify these two approaches as content-based approaches. Burke also identifies seven different methods that have been used to create hybrid-filters between the five different approaches [hybridization methods] , where combinations between the collaborative approach and some of the other approaches using some of these methods are the most common ones.
| Weighted | By using two or more approaches, each approach's recommendations can be weighted against each other on how much they should affect the final recommendation for an item. |
| Switching | The recommender system switches between different approaches depending on the situation. |
| Mixed | Recommendations from different approaches are presented at the same time to the user. |
| Feature combination | User and item data is combined into a single profile. |
| Cascade | One approach refines the recommendations given from another approach. |
| Feature augmentation | The output from one approach is used as input feature to another. |
| Meta-level | The model learned by one approach, is used as input to another approach. |
hybridization methods
Problems and challenges of the recommendation approaches
The content-based and collaborative approach have their own weaknesses and strengths, a natural way of solving this is to create hybrid filters. The manual and statistical approaches don't suffer from the problems that these approaches have because they provide non-personalized recommendations. We start by identifying some of the issues with collaborative filtering that have been addressed in the literature and then we go on with the content-based approach.
The collaborative filtering approach - weaknesses and strengths
- First rater problem
A new user can't receive any recommendations before the system has learned what preferences the user has. One common way of solving this is to ask the user to rate a fix number of items before making any recommendations to the user. This approach is used in the MovieLens system where every new user to the system must rate at least twenty movies before the user can start to use the system and receive recommendations for movies.
- New item problem
A new item can't be recommended until enough people have rated it in a collaborative filtering system. Sarwar et. al solves this in [sarwar98using] by the use of filterbots that are programmed software agents. These filterbots rate new items when they arrives to the system by analyzing the content of the items and comparing it to their own rating profile, i.e. in a movie domain some filterbots are specialized in a particular genre and will therefore rate movies that belongs to that genre highly.
- Sparsity
Sparsity deals with the fact that most users only have observed few items or that most of the items only have been observed by a few users. This has consequences when it comes to the coverage, i.e. the recommender system's ability to recommend all items and the accuracy of the given recommendations. With sparse data users will most likely only overlap on a few common items, resulting in recommendations based on questionable data. Several methods have been proposed to deal with this problem. One approach is to add more data into the similarity calculation. This can be done as in [mellville02conentboosted] where they extend the user profiles with content-based ratings. A different approach is to reduce the dimensionality of the rating matrix by the use of singular value decomposition as in [sarwar00application] or Principal Component Analysis as in [goldberg01eigentaste] . Although, some of these methods manage to produce slightly better recommendations there are some trade-offs, valuable information can get lost by the reduction of data and the adding of extra content to the user profiles means that more information must be gathered, which is not always an easy task.
- Scalability
The main drawback with the collaborative approach is that the computations are very expensive because of the high dimensional spaces of users and items. The memory based techniques requires that the whole user-item database is kept in memory, however when the database of users and items grows this approach fails to scale up. Different solutions to this has been proposed, like the ones in the paper by Breese [breese98empirical] where model-based techniques are used as described earlier. In [oconner99clustering] they experiment with different kinds of clustering algorithms in an attempt to increase scalability and accuracy of predictions. The clustering algorithm is used to make smaller partitions of the item space where each partition contains items that have been found to be similar according to how users have rated them. After the partitions have been found, collaborative filtering is applied to each of the partitions, independent of each other. They report a mixed result for the accuracy of the predictions but they suggest that clustering algorithms do increase the scalability of the collaborative approach. Another technique is proposed in [sarwar01itembased] where they apply singular value decomposition to reduce the dimensionality of the user-item matrix. Although these techniques report improvements on the performance they usually reduce the quality of the recommendations, i.e. "What you gain in performance, you loose in quality" . Models also need to be rebuilt to reflect the changes in the user profiles, this is done off-line but it usually takes some time and during that phase, user profiles are not up to date. Some simpler techniques like discarding popular and unpopular items reduces the dimensionality but at the cost that some items will never be recommended. The trade-off between quality and performance is something that must be considered and adjusted to the domain that the recommender system operates over.
- Grey sheep problem
Users with unusual or divergent taste can have trouble in finding users with similar taste to serve as recommenders. It can also be the case that the kind of items these users like have too few ratings to even be considered in the recommendation process. The use of content-based predictions as in [mellville02conentboosted] is one proposed solution to this.
Some of the advantages with the collaborative approach is that it doesn't require any representation of the items, only the rating data, making it suitable for domains where item descriptions are hard to make. Another issue is that it can offer a quality measure of items, i.e. items that are highly liked by a majority can serves as an indication of the quality of the item.
Based on these observations, the collaborative approach is best suited for users that can be matched with many other users and in an environment where the density of user ratings are relatively high and the item domain is small and static.
The content based filtering approach - weaknesses and strengths
Content Representation - Content-based approaches are limited by the attributes that are associated with the items. Obviously, if the item lacks descriptive attributes, it can't be used in a content-based approach and for items like graphical images and audio, it is very troublesome to find descriptive attributes. Another issue is that the content must be added by someone, which can be a costly and tiresome process, and in some cases not even practical [shardanand95social] . However, the main problem is to find those attributes that contains the most descriptive and significant information about the item, which is often very domain dependent.
- Limited Content Analysis
If two different items are represented with the same attributes, this approach can't distinguish between them. For example, in text-analysis a document is usually represented with its most important keywords, this approach can't distinguish between a badly and a well written article, if they use the same terms.
- Serendipity problem
Since the system only recommends items that matches the user profile, the user will only receive recommendations that are similar to the items the user has already encountered. This leaves little room for new experiences or serendipity and can lead to the user getting tired of the recommendations since the recommendation system seems to only be able to recommend items that the user would have discovered anyhow.
- New user problem
The system can't recommend any items before it knows the user's preferences. In the content based approach, the active user's preferences is the only factor that has influence on the recommendations, fewer preferences means less accurate recommendations.
Advantages with the content-based approach is that a new item can be recommended without anyone else having given their opinion on it, thus it doesn't suffer from the new item problem as described in the collaborative approach. Sparsity and scalability is not an issue, since no matching between users is made, only between users and items.
One problem that both approaches shares is the new user problem, the fact that without enough user preferences, the recommendations will suffer in accuracy. Although the content-based approach has the advantage that it actually can recommend items based on less information about the user than in the collaborative approach. In the content based approach, even if the active user has only rated one item, recommendations of items similar to that particular item can be made, but in the collaborative approach, if two users have one item in common, it gives no indication whatsoever about whether or not they have the same taste and needs.
Case studies of recommender systems in the movie domain
One domain that is well suited for recommender systems is the movie domain. Many movies are just waiting to find their audience but due to the enormous amount of movies, both old and new ones, it can be troublesome for the average movie viewer to find the movies that appeals to his taste. And for the so called movie "cineasts", discovering those new and old gems beyond ones imagination can be equally challenging. Movie sites on the Web offers a solution to this in many various ways, for example, the visitor can browse around the site for information on old and new movies, he can search for information regarding movies using criteria's such as who stars in a particular movie, who directed the movie, etc., and he can receive recommendations on movies based on his personal taste in movies. We will be looking at four different websites that operate in the movie domain to see what kind of features they have incorporated into their sites as a way of making it easier for a user to find the information that meets his needs regarding movies. The main focus will be on their recommendation technique; how they work and with a subjective opinion by the authors on how well they work . Other features that we have found interesting will also be studied and reviewed. We will also compare the recommendation from each one of recommendation systems on the basis of one movie that we like, namely the movie "The Thing" by John Carpenter
MovieLens
MovieLens is a movie recommendation website that is part of the GroupLens research project at the University of Minnesota. They built MovieLens as a platform for researchers to experiment on in areas related to recommender systems such as recommendation algorithms, recommendation interface design, online community integration etc. By using MovieLens and (optionally) participating in various studies the users contribute with important feedback that helps the researchers to developed and improve MovieLens. However, for most people, MovieLens is just a fun experience where you can receive predictions for movies you haven't yet watched.
Recommendations
MovieLens gives predictions on movies as well as non-personalized recommendations . MovieLens also provides a Top-N list of all movies that the system can make predictions for sorted in descending order of prediction.
Predictions
Before you can get any predictions, you must become a member and rate 20 movies [movielens welcome screen] , that the system randomly chooses, on a scale from 1 to 5.
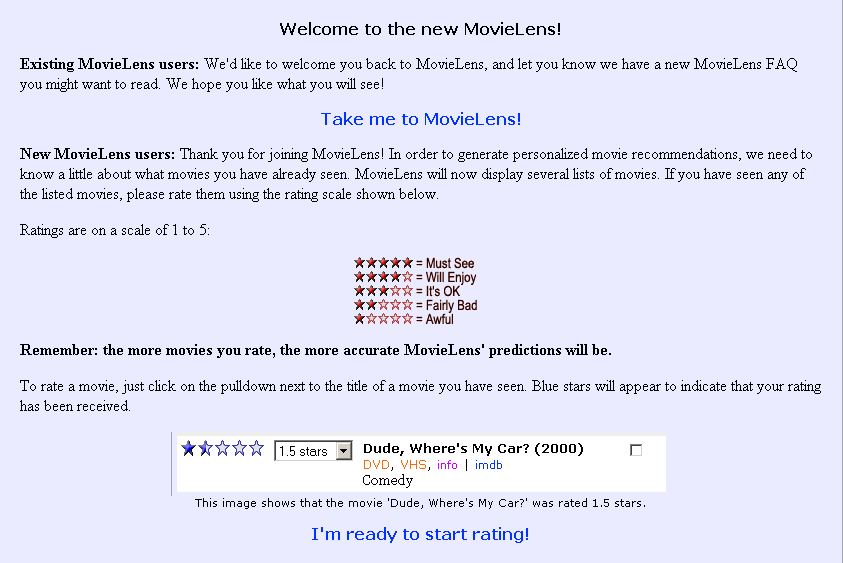
movielens welcome screen The MovieLens welcome screen after you have become a member.
The ratings for the 20 movies are used by MovieLens to predict ratings [movielens interface] on movies that you haven't yet rated. As a member you are encouraged to rate more movies in order to fine tune the accuracy of the predictions that are given to you.

movielens interface The MovieLens interface. Recommendations are in red stars. You can rate movies you have seen by using the menus.
Non personalized recommendations
Recently, MovieLens added a new recommendation service called "QuickPick: Our Movie Gift Recommender" which is (more or less) a non personalized recommendation service. You don't need to be a member of MovieLens to use it, just enter the name of one movie that you like and MovieLens will use that movie to find other movies that people have expressed similar opinions about. It's however also possible to enter the name of multiple movies you like and fine tune the recommendations by making them more personalized. This recommendation service is based on the same technique as that used for making predictions within the MovieLens system. [movielens quickpick] shows the recommendations we got for the movie "The Thing".
movielens quickpick Recommendations for the movie "The Thing" given by MovieLens QuickPick recommendation service.
How it works
With reference to a discussion with one of the developers of MovieLens, we will now give brief description of the recommendation technique MovieLens uses and some issues related to it.
MovieLens is based on the collaborative filtering approach, before 2003 the recommendation technique they used was a neighborhood based CF technique, i.e. a user based CF technique. That technique used the Pearson correlation coefficient to determine similarity between users and the weighted deviation from mean prediction formula. Different tweaks (extensions) to the technique was also used, such as only using a relatively small number of the most similar users as recommenders for the active user. Some of the researchers in the GroupLens team founded Net Perception Inc. and brought the source code for the recommendation technique MovieLens was relying on with them, since this was a commercial company the source code became closed sourced. Doing research on a closed sourced recommendation technique makes it hard to maintain and perform new experiments, this was the main reason for a shift to a new recommendation technique.
The new recommendation technique that is currently in use by MovieLens is an item based CF technique. Instead of computing similarity between users, the technique computes similarity between pairs of movies (still only relying on user ratings on movies). The movie similarity is then used as a weight in the prediction process. Thus when the active user wants a prediction for a movie (the active movie), the technique will find the 20 movies that the active user has rated that are most similar to the active movie. Note that it will almost always be possible to determine similarity between the active movie and the movies the active user has rated since MovieLens precomputes and stores all item similarities (as opposed to only storing the k highest similarities for each item), however in some cases item similarity can simply not be determine due to missing data. The ratings for each one of these 20 movies are then weighted against their similarity with the active movie and summed up. The average of this weighted sum of ratings is rounded to the nearest half decimal and presented to the user as a prediction on the active movie. Exceptions to the prediction process occurs when the active user's 20 most similar movies to the active movie aren't that similar, then the active movie's average rating (by the whole population) is instead used as a prediction. Additionally when the active movie has been rated by too few users, no prediction at all will be given.
Does it work?
The way the recommendation technique is implemented makes it very conservative. Users with low average ratings will rarely, if ever, get any 5 star predictions. Another reason it's conservative is that in the prediction process, it will almost always find 20 movies to compute predictions with and unless the user has rated these movies very high (or low), the predicted rating tends to be near the user's average rating.
Remember that it is the 20 most similar movies out of those that the active user has rated that are used, this means that their similarity isn't necessarily very high, that is a side effect of storing and using all item similarities as opposed to only storing for each item its highest similarities. However, it does ensure that predictions will almost always be possible.
Another interesting issue is the difference in accuracy between the predictions made by the new item based CF technique and the old user based CF technique, says one of the developers of MovieLens. The item based CF technique (as implemented) tends to generally be accurate but often, as mentioned, makes predictions near a user's average rating. The user based CF technique (as it was implemented) could be much more speculative, though occasionally wrong. He believes that this can have something to do with the fact that it typically used a total of 50 other users, that had "just one or two ratings [sic]" in common with the active user. Maybe this is the tradeoff that has to be considered for every recommendation technique, should the recommendations be safe and nearly boring or should there be more serendipitous in the recommendations with the risk of giving recommendations that are very wrong in some cases?
Browsing
MovieLens is not a place for browsing around and looking for information about movies. First of all, you need to become a member before you can even take part of the information that is available, and secondly, MovieLens is designed to predict ratings for movies, not to serve as an information source about movies. They do provide some brief information about movies such as title, genre, release year, main cast and director. But for further information they provide a direct link to another movie website (IMDb).
Searching
They support both simple and advance searches, i.e. search by genre, title, main cast, language etc. The search results can be sorted by prediction, title, number of ratings to name a few. You can also use short-cuts, which are pre-defined searches and you can create your own shortcuts. Examples of pre-defined shortcuts are "Top picks for you" and "Your ratings".
Other features
MovieLens has started to implement features that encourage people to more actively participate in the website, such as discussion forums , allowing users to edit movie information and letting users tag movies. Tags are words or phrases that are added to the movies by the users. Movies with tags can be organized, searched, classified etc. by their tags. Tags are however currently not used in the recommendation process, it is simply an additional source of movie information. Another nice feature is called buddies , you ask other MovieLens members to become your movie buddy and can then view both their predictions for movies and a combine prediction score that reflects the average prediction for the movie among you and your buddies.
Internet Movie Database
The Internet Movie Database (IMDb), started out as a Usenet newsgroup(*) back in the early 1990's and is now a part of the Amazon group. It is considered to be the largest movie database on the Web, covering nearly 500 000 movie and TV titles. With over 30 million visitors each month and with nearly 9 million registered users, it can be considered to be one of the most popular sites on the Web.
Browsing
The front page of the website invites a user to start browsing around in a multitude of ways, there are shortcuts with names like top 250 lists, news articles, movies now playing in the theatres, award winners, movie quotes, movie of the day, etc. They even have a shortcut with the name "Browse" that takes you directly to the directory of all IMDb's features. So, finding movies by browsing is easy, just a few clicks and you will have found a couple of movies that might be of interest.
Searching
So, what about its searching capabilities, how easy is it to find a movie that your favorite director or actor and actress has been involved with? Easy, the front page allows searching the whole database on all attributes or based on a specific attributes like title, plot summary, keyword, etc.
Recommendations
IMDb has what they call a recommendation center , which to them is just one of many features they have incorporated into their site, so no particular effort is made to promote it to the users. Other popular features are for example their message boards, user comments, user votes for movies, goofs, trivia, plot summaries etc. For a complete list and a detailed explanation of all the features offered by IMDb, see IMDb's A-Z Index(*) .
Nevertheless, the user can receive recommendations for movies either by going to the recommendation center and type in the name of a movie or in connection with a movies information page, follow a link named "recommendations", this will give the user recommendations based on the assumption that he likes the movie in question. Since the recommendations are the same for every user, they are non-personalized. [imdb recommendation center] shows the recommendations we got for the movie "The Thing" when using the recommendation center.


imdb recommendation center Recommendations for the movie "The Thing" given by IMDb's recommendation center.
How it works
How their recommendation technique works is a bit unclear, the only explanation they give is that "It isn't feasible to handpick Recommendations for every film. That's why we came up with a complex formula to suggest titles that fit along with the selected film and, most importantly, let our trusted user base steer those selections. The formula uses factors such as user votes, genre, title, keywords, and, most importantly, user recommendations themselves to generate an automatic response." Since the recommendations are the same for every user, they are non-personalized. Probably some content-based technique that matches the features of the movie against another movie is used, possibly combined with users ratings.
Does it work?
If someone would suggest these movies to me I would think he had a pretty good taste in movies, but if someone asked me for recommendation on movies similar to the Thing, then most of these movies wouldn't make the list.
Other features
In the IMDb database most of the movies have one or more (plot) keywords associated with them, these keywords are manually added descriptive keywords of a movie, for example the movie "The Thing (1982)" has keywords such as "Paranoia", "Alien", "Flame Thrower" and "Ice" associated with it. The movie keyword analyzer (MoKA)(*) is a relative new feature added by the folks at IMDb which allows filtering movies by their keywords, say for example that you are in the mood for some gore, just enter the keyword "Gore" in the IMDb keyword search as the starting keyword for your exploration. A list with keywords matching the serach will be shown with the word Gore displayed at the top and the information that there's 2082 titles somehow related to the keyword Gore! Partial matches of the word gore like "Gore-film" and "Al-gore" as well as approximate matches like "Hero-gone-bad" will be shown. Each matching keyword on the list will take you to the complete list of titles that somehow is related to the chosen keyword. We choose to follow the link for the keyword Gore which after all was what we were interested in. And Voila! A list of all the 1019 titles that feature this exact keyword is presented for us together with a related keywords map [imdb moka1] .


imdb moka1 Part of IMDb's MoKA keyword map for the keyword "Gore" together with the 25 (out of 1019) highest rated movies featuring the keyword.
The related keywords map consists of all the different keywords that are associated with at least one of the 1019 Gore movies. Together with the keyword is a number that indicates how many of the Gore movies that are associated with the each keyword, by clicking on one of the keywords, we can narrow down the list of movies. We choose to click on the keyword "Blood" since we want some blood in our Gore movie as well. This action reduces the list to 590 movies that all feature both the keyword Gore and the keyword Blood. A smaller related keywords map showing all keywords that are featured in at least one of the remaining 590 movies is shown [imdb moka2] . Narrowing the search down further to include also the keyword "Exploding head" results in 48 movies [imdb moka3] . As there is still too many movies to choose from, we narrow it down by selecting the word "Zombie" and end up with 16 movies [imdb moka4] .


imdb moka2 Part of IMDb's MoKA keyword map for the two keywords "Gore" and "Blood" together with the 25 (out of 590) highest rated movies featuring the keywords.


imdb moka3 Part of IMDb's MoKA keyword map for the three keywords "Gore", "Blood" and "Exploding head" together with the 25 (out of 48) highest rated movies featuring the keywords.


imdb moka4 Part of IMDb's MoKA keyword map for the four keywords "Gore", "Blood", "Exploding head" and "Zombie" together with all 16 movies featuring the keywords.
Finally we choose the word "Disembodied Hand" [imdb moka5] , leaving us with three movies, of which the one with the highest user rating is entitled "Evil Dead II" , sounds like an interesting movie, lets watch it! As [imdb moka5] shows the remaining three movies have a lot of keywords associated with them, however further narrowing seems pointless.


imdb moka5 Part of IMDb's MoKA keyword map for the five keywords "Gore", "Blood", "Exploding head", "Zombie" and "Disembodied Hand" together with all 3 movies featuring the keywords.
This way of letting the user select keywords and also see how the resulting list narrows down to just a few movie titles is fun and inspiring, you wonder what kind of movies will be left that corresponds to this list of keywords. The keyword map itself is nothing special, its just a rectangular map with the keywords in alphabetic order with words that appear in many titles in more bolder style than keywords that appears in fewer movies. But its more fun to pick keywords this way than from a vertical list or by figuring them out by your own.
All Movie Guide
All Movie Guide ("Allmovie")(*) is a searchable database of movie related information that covers over 260.000 movies. Just like IMDb, the site has a number of different features for finding movies. You can for example search for movies with two people in common or you can search for people with two movies in common.
Browsing
On Allmovie's front page you are presented with selections of movies and related information to start out with under headings like trailers, new DVD releases, essays about movie related subjects, movies now showing in theaters. There is also have a feature called Quick Browse that lets you browse movies by genre, country and time period. A bit modest compared to IMDb's front page, but it will get you started.
Searching
A search option is available at the top of each page but, strangely, there is no advanced search option anywhere. Two funny search options entitled film finder and people finder are however available. The film finder lets you type in the name of two people and see if they have a movie in common. The people finder lets you type in the name of two movie titles to see which people they have in common.
Another feature is glossary, which is a reference source for a wide variety of movie and film-related terms written by experts in the field with various search capabilities. The glossary includes an explanation for all kinds of movie related terms which can be of help in the search process.
Recommendations
The user can't ask for recommendations, instead, the webpage for a particular movie contains not only the movie's attributes (which there is often an abundance of!) but in many cases also three different lists of movie recommendations. They have choose to categorize their recommendations as; similar movies, movies with the same personnel and other related movies. The title of the movie is presented with its release year and director. Since the recommendations are the same for every user, they are non-personalized. [amg recommendations] shows the recommendations we got for the movie "The Thing".

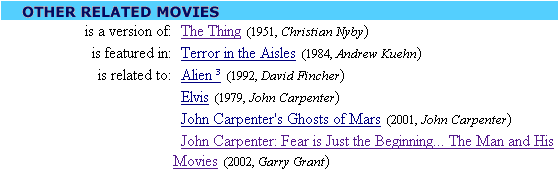
How it works
As opposed to IMDb, these recommendations are manually selected by experts working for Allmovie, at least according to the answer we got from them when we asked them how the recommendations were made.
Does it work?
One can tell by looking at the recommended titles that there has been some effort behind these recommendations, they aren't just picked because they are in the same genre or something trivial, it's more because they share the same mood or have a similar plot, something not quite graspable but definitively similar. Unfortunately, you can't choose any movie you want as seed movie for the recommendations, as in the IMDb case, since not all movies have a recommendation list on their information page.
Amazon
If I have 3 million customers on the Web, I should have 3 million stores on the Web.
Jeff Bezos, CEO of Amazon.com
Amazon is an American e-commerce company that started out in 1995 as an online bookstore. Due to its growing popularity it didn't take long before Amazon also started selling other products such as CDs, DVDs, computer software, gourmet food, musical instruments, toys, etc. As a customer visiting Amazon you are faced with so many options and products to choose among, that without some guidance you will probably real soon get lost. To overcome this problem, Amazon has come up with a variety of solutions for enhancing the customer's shopping experience. The solutions can be divided in the following three categories:
- Site features
Recommendations of various kinds shown while browsing the webstore for products.
- Your community
Provides, among other things, personalized recommendations and different ways for customer to interact with each other.
- Notifications & E-mail subscribing
An e-mail service that sends recommendations for new items or other interesting news that the customer has choose to be informed about.
Our focus will be on what kind of site features Amazon.com has incorporated into their movie section, i.e. the DVD section. Some community features will also be discussed, such as tagging, rating and reviews.
Browsing
Amazon's DVD section is filled with different browsing options. You can browse by genre, top sellers, new & future releases, blockbusters, offers, etc. The trick is to lure the visitor into browsing and by that process convert the visitor into a buyer. Amazon does this with the help of different site features where recommendations play the major role.
Searching
Amazon offers both a simple search and an advanced search with the usual list of search options for movies, such as title, actor, director, genre, etc. One interesting search option allows searching for special features on the DVD, like alternating endings, deleted scenes, etc.
Amazon also has their own search engine called A9(*) , that allows customers to search the internet. Interesting about A9 is that it uses the customers account information to provide personalized search results as well as the users search history.
Recommendations
To get the most out of the recommendations, Amazon suggests that every user become a member of Amazon's community by setting up an account. In order to buy something from Amazon, the user must create an account, so every customer is by default also a member of the Amazon community. After a user has become a member, Amazon activates a feature called Your Store [amazon your store] . This feature gives the user access to a range of features only available for members. Among those features is the ability for a member to improve his recommendations by giving explicit feedback about his preferences.
amazon your store All the features that are enable from "Your Store"
Every time the customer visits Amazon, he can log into his store and receive recommendations that are based on his own taste [amazon your store recommendations] .
amazon your store recommendations Amazon provides a list of personalized recommendations to members in their Your Store feature.
Amazon also keeps track of all the items that a user has viewed and searched for, and the type of product categories that have been visited, during the current visit. This kind of implicit information is then used by a feature called The page You made and Your recent history [amazon page you made] to create recommendations based on the interests shown during the current visit.
amazon page you made Recommendations for the movie The Thing given by Amazon on their Page you made feature, which bases recommendations primarily on products viewed during the current visit to Amazon. The top four recommendations out of totally twenty are shown in the figure.
Amazon also supports non-personalized recommendations. For example when a customer is viewing the product page for an item, in this case for the movie The Thing, recommendations of the form "Customers who bought/viewed this item also bought/viewed these items" or "Better together" (Amazon.com suggest an item that they think the customer should buy together with the one currently being viewed) are shown [amazon product page recommendations] .
amazon product page recommendations Recommendations for the movie The Thing shown at the product page for the movie.
A customer at Amazon has his own shopping basket, when the customer adds something to the shopping basket or just views its contents, a page with recommendations is shown [amazon shopping basket recommendations] . These recommendations are based on the current contents of the shopping basket and on the item (if any) just added to the shopping basket. Recommendations are of the type "Customers who bought/shopped/viewed the items in the shopping basket also bought/shopped..." This feature provides a nice browsing experience, where users can always easily find a interesting path to continue browsing on after finding a product interesting enough to add to the shopping basket.
amazon shopping basket recommendations Recommendations shown when a customer views the contents of the shopping basket, in this case the shopping basket contains only the movie The Thing. The recommendations are based on the items currently in the shopping basket.
How it works
According to the paper written by Linden [Linden et al., 03], Amazon.com's recommendations are based on what Linden calls item-to-item collaborative filtering . It is clear that the recommendation engine uses the purchase history of customers, since this is mentioned both in the paper and several times at the Amazon.com website. However, they also mention that customers ratings on items and items that the customer has specified he owns are used in the recommendation process with the possibility to exclude specific items from the recommendation process. So they have probably implemented some tweaked version of the recommendation technique described in the paper. Also what is interesting is that Amazon supports short termed user profiles containing e.g. browsed products as opposite to long termed user profiles consisting of e.g. the user's purchase history. The short termed profiles of a customer can be found in the feature The page you made , where the customers recent activity on the web-site can be found together with recommendations based on those activities. The support of both short termed user profiles and long termed user profiles is something that are considered to be highly important, and is referred to respectively as ephemeral recommendations and persistent recommendations in [Schafer et al., 01]. By giving ephemeral recommendations, the recommender system hopes to catch the customers immediate need and change in taste for, in this case, movies.
Does it work?
In the authors opinion, it works well, but it is quite obvious that Amazon goes for safe recommendations, probably because the customer is more willing to buy something he is familiar with than going for something completely new and risky. Amazon makes sure to always motivate their recommendations to some degree, usually by simple but clear formulations such as "Customers who bought item X also bought..." but in certain cases also by showing which exact purchased products resulted in a specific recommendation. The system is easier to trust and, at a user level, to understand thanks to the usages of these motivations. By supporting different kinds of recommendations, Amazon makes sure that they can always give recommendations that to some degree are based on the customers preferences.
Other features
When the customer visits a product page, he is not only faced with recommendations and facts about the product, he can also read what the Amazon user community thinks about the product. Some of the features that appears on the product site for a DVD in Amazons DVD-section are:
- Customer reviews and ratings
Every customer that is a member of the Amazon.com community can write reviews and rate items. This allows for other customer to see what previous customer thought about the item.
- Listmania!
Shows lists created by customers. The feature in general allows customers to create lists about just everything. The lists shown on a product page have some kind of connection to it and serves as a kind of related products list.
- So you'd like to...
Allows customers to help each other find items and information that may be relevant in connection with the product. For example, for the movie The Thing there is a guide named "So you'd like to... get scared" out of your wits, this guide contains information about other movies that the writer of the guide thinks would interest a person that likes The Thing in the sense that the person also likes to get scared.
- Customer tagged this item with
Tags are word or phrases that are given to items, in this case movies. The main purpose of showing the tags for a movie is in the hope that they contain some meaningful information that are of interest to the customer, and to provide another way of browsing movies as it is also possible to click on the tags to see what other movies have been tagged with the same tag.
- Customers that tagged this item
Shows names of people that have tagged the movie, by clicking on their names the customer is taken to the person's Amazon homepage . The Amazon homepage contains more information about the person who tagged the movie, such as other movies they have tagged, which might provide yet another way of browsing for movies.
Recommendations for the movie The Thing
Since the recommendation systems that we have review is based in some cases on different techniques and operates on different background data but in the same domain, we thought it would be interesting to see if there is any big difference among the given recommendations. To test this in a slightly subjective way we gave each recommendation system one movie to base their recommendations on, the movie we used was The Thing directed by John Carpenter in 1982. [the thing recommendations] present all recommendations that are given for the movie The Thing by the different recommendation systems.
| MovieLens | Amazon.com | IMDb | Allmovie.com |
| QuickPick: Our Movie Gift Recommender | Customers who bought this DVD also bought | Recommendation Center | Combined Similar movies Movies with same personnel Other related movies |
| For a Few Dollars More (1965) | The Fog (1980) | Dawn of the Dead (2004) | Endangered Species (1982) |
| Ringu (1998) | They Live (1988) | Day of the Dead (1985) | Hiruko the Goblin (1990) |
| Hard-Boiled (1992) | Escape from New York (1981) | Alien: Resurrection (1997) | Night Beast (1983) |
| The Killer (1989) | The Thing from Another World (1951) | Doom (2005) | Body Snatchers (1993) |
| Alien (1979) | Prince Of Darkness (1987) | The Lord of the Rings: The Return of the King (2003) | Boa (2002) |
| Aliens (1986) | An American Werewolf in London (1981) | War of the Worlds (2005) | Alien (1979) |
| City of God (2002) | In the Mouth of Madness (1995) | Sin City (2005) | The Fly (1986) |
| Evil Dead II (1987) | Land of the Dead (2005) | Dawn of the Dead (1978) | The X-Files: Ice (1993) |
| Battle Royle (2000) | Big Trouble in Little China (1986) | Terminator 3: Rise of the Machines (2003) | Shadowzone (1990) |
| The Evil Dead (1981) | The Shining (1980) | Freddy Vs. Jason | Halloween (1978) |
| Once Upon a time in the west (1968) | Assault on Precinct 13 (1976) | Alien (1979) | Dark Star (1974) |
| The Outlaw Josey Wales (1976) | Halloween (1978) | An American Werewolf in London (1981) | The Fog (1979) |
| Alien (1979) | The X Files (1998) | Prince of Darkness (1987) | |
| Sin City (2005) | The Terminal Man (1974) | ||
| Invasion of the Body Snatchers (1956) | Escape from New York (1981) | ||
| AVP - Alien Vs. Predator (2004) | They Live (1988) | ||
| Predator (1987) | The Mean Season (1985) | ||
| Poltergeist (1982) | The Thing from Another World (1951) | ||
| The Exorcist (1973) | Terror in the Aisles (1984) | ||
| Escape From L.A. (1996) | Alien3 (1992) | ||
| Elvis (1979) | |||
| Ghosts of Mars (2001) | |||
| John Carpenter: Fear is Just the Beginning... The Man and His Movies(2002) |
the thing recommendations
We can make the following observations based on [the thing recommendations] :
MovieLens shows 12 recommended movies when using their QuickPick service.
Amazon shows 20 recommendations when asked for recommendations on the form of "Customers who bought this DVD also bought..." . Note that Amazon as mentioned provides many more different types of recommendations ("Customers who bought/shopped/browsed/tagged" etc.), we picked the most common and what we consider prominent type of recommendation for this comparision.
IMDb shows 13 movies in their "Recommendation center" although the last recommendations are not based on their recommendation algorithm, instead those are recommended using the motivation "The monster inside you" (the 11th and 12th recommendation) and "IMDb users recommend" (the 13th recommendation).
Allmovie groups three categories of recommendations, "Similar movies" , "Movies with the same personnel" and "Related in other ways" , together into one listing. In this comparision this was the longest list of recommendations.
The plot synopsis for the movie The Thing on the IMDb reads as follows "An American scientific expedition to the frozen wastes of the Antarctic is interrupted by a group of seemingly mad Norwegians pursuing and shooting a dog. The helicopter pursuing the dog crashes leaving no explanation for the chase. During the night, the dog mutates and attacks other dogs in the cage and members of the team that investigate. The team soon realizes that an alien life-form with the ability to take over other bodies is on the loose and they don't know who may already have been taken over."
A closer look at Allmovies list of "Similar movies" reveals that the common theme among these movies seems to be the unknown desire for flesh - particular human flesh - either by consuming it, remodeling it, or by just taking over the whole body. For example "The Thing" has one scene where a human head turns into a spider-like creature, and the movie "Hiruko the Goblin" is about demons that decapitate humans and uses their heads on spider-like creatures to fight humanity. The scene where the dog mutates can be thought of as similar to the plot in the movie"Endangered Species" where the town sheriff starts to investigate the rash of cattle mutilations - is it caused by extraterrestrials or is it the government that is behind it?.
Amazon recommends eight movies directed by Carpenter and most of the other movies belongs to the Horror and Alien genre. One movies that stands out from the rest is "The Thing from another planet", another adoption of John W. Campbell's short story "Who Goes There?", the short story that "The Thing" is also based on. Another recommendation that stands out from those given is "Sin City", which can perhaps be seen as a slightly serendipitous recommendation.
The recommendations from IMDb seems to be either Alien or Gore movies with the exception of the movies "The Lord of the Rings" and "Sin City". Notable is that none of the recommended movies are directed by Carpenter.
MovieLens offer the most divergence among the movies that are recommended, no obvious common theme can be detected and the movies belongs to a broad category of genres like westerns, horror, Hong Kong action, drama, gore and alien movies. Also here we notice that none of the recommended movies are directed by Carpenter.
The recommendations given by Amazon and IMDb seem to be very genre dependent, i.e. since "The Thing" by mainstream media is usually categorized as a Alien(Science fiction)/Gore/Horror-movie, the recommended movies will also be from these genres. Amazon's dependency seems to also include directors, since it recommend a lot of movies from the same director. All the recommended movies are also very known movies in their respective genre and some are known even for the broader movie public. We would categorize the recommendations from Amazon and IMDb as very safe ones, a user who receives this kind of recommendations would probably not be disappointed, which is of great importance for a web-store like Amazon, since a disappointed customer could led to loss of money. However, showing the customer only movies he already knows about, it is highly likely someone purchasing a movie by John Carpenter is familiar with his other movies, might lead to the customer ignoring the recommendations completely in the long run. It's a difficult balance.
When it comes to a web-site like IMDb, it wouldn't hurt with a bit more serendipity among the recommendations, since the risk of making a bad recommendations is less expensive than for a web-site that makes a living out of selling movies. The overall judgment is that for a person who is unfamiliar with the genres that the movie "The Thing" belongs to, IMDb provides some decent recommendations, but for someone familiar with movies from these genres, chances are very high that he has already watched all the recommended movies.
Allmovie had the most interesting recommendations, their viewpoint is that movies with similar themes are good recommendations. The serendipity factor is high since the movies can be classified as non-mainstream movies, compared to movies like "Alien" and "Dawn of the dead", that are movies that are well-known in their respective genre. If you want to be introduced to new genres and movies you otherwise wouldn't come across, then Allmovies is a good place. The major drawback with their recommendation technique is the fact that it is made manually, which has the consequence that recommendations are not given for all movies and can at times become too subjective.
MovieLens was the web-site that gave the most divergent recommendations, ranging from a wide variety of genres and mostly with no obvious common theme between the movies. All the recommendations, with one exception "City of God", were movies the authors had previously seen and enjoyed. The recommendations have certain elements of similarity. Looking at the recommendation Alien, we find a recommendation given by all the other recommender systems too. A safe recommendation, that can be seen to have both elements of science fiction and elements of atmosphere in common with the seed movie. However, most of the recommendations are not so obvious recommendations. For example "The Killer" and "Hard Boiled" is suggested, two Hong Kong movies where more bullets are fired each minute then there are seconds in an hour[sic]. Based on the authors own movie taste those two movies would actually be good serendipitous recommendations to someone who likes The Thing. Since MovieLens makes recommendations based on the collaborative "people who liked this movie also liked these movies" approach, indeed the basic motivation behind the recommendations is precisely such subject opinions, however not among only the authors, but among a larger group of people. The authors considers it a good sign for a recommender system to be able to make such leaps between apparently divergent genres and themes, that still retain a level of relevance and interest to the receiver of the recommendations.
While browsing a web store such as Amazon might one might expect recommendations to constantly retain a clear relevance and possibility for easy motivations, as such making serendipitous recommendations like MovieLens might be difficult. However, nothing prevents a web store from including such recommendations, in the hopes of steering a customer into new areas of interest.
Conclusions
Movie databases like IMDb and Allmovie are databases that are loaded with facts about and around movies, thus much effort has been put into their searching and browsing features. When it comes to recommendations, Allmovie goes for quality rather than quantity compared to IMDb. The authors have found that the manual recommendations given by Allmovie is often of more value then those given by IMDb. On the other hand is IMDb loaded with more movies and information and rich with features for filtering this information, which is often more useful. Amazon, the only strictly commercial web-site in this review, tries to please its customers rather than surprise them and risk negative feedback. Nevertheless, by setting up an account and telling Amazon who you are and what your interests are, your shopping experience will be enhanced. The authors have been particularly pleased with as an experiment shopping for 80's slashers at Amazon and relying only on the recommendations trail given when first adding the movie Text Cheerleader Massacre to the shopping basket. MovieLens, an ongoing research project, does take risks and elaborates with their recommendations as well as their web-site since that is the nature of their research. The authors have found that the non-personalized recommendation service gives very good recommendations, but the authors experience of the systems ability to make personalized predictions for movies hasn't been as positive. Most of the predictions were near the authors average rating (including movies the authors weren't very fond of) and predictions that consists of extreme ratings such as 1 star or five star were very rare, similar as to what was commented on by one of the developers.
Patents
During the years, several patents for recommender systems have been granted by the U.S patent and trademark office, some notable ones is Cendant Publishing's patent "System and method for providing recommendation of goods or services based on recorded purchasing history" in September 4, 1997 [stack97patent] and Amazon.com's patent "System and methods for collaborative recommendations" filed in March 17, 1998 [jacobi98patent] . There has been, and still is, a lot of debate around these and other similar patents. Companies are suing each other for using what they claim to be there inventions, as an example Cendant sued Amazon for infringed on their "370 patent" for providing people with recommendations of goods or services to purchase based on a database of previous purchasing histories of other customers. The suit was filed Oct. 29 2004 [kawamoto04cendant] .
Where are we today?
From originally having being a research question about "How to do it?" the question has after the ACM SIGIR'99 workshop in recommender system become a question of "How can we do it better?" and "How do we know it's better?" .
Herlocker, one of the co-founders of GroupLens, addressed thesse issues in his dissertation [herlocker00understanding] on recommender systems based on the collaborative approach. Herlocker tested over 1800 different collaborative filtering techniques and also goes through the different kinds of metrics that have been used to evaluate recommender systems. Based on the results, he gives a framework for designing recommender systems based on the collaborative filtering approach and what metrics are to be used to evaluate the systems. He also tackles the problem of explaining the recommendations for a user by conducting an on-line research where different recommendation interfaces are shown to a group of users.
In 2001, the SIGIR 2001 workshop for Recommender systems was held as a follow up to the SIGIR'99 workshop. This time the workshop was hosted by Herlocker and the theme was now "algorithms, applications, and interfaces" . As an attempt to get a clearer picture of the ongoing work in the field of recommender systems, all individuals or groups that are involved in the research, development or production of recommender systems are encourage to submit a one page summary of their work to the workshop. These will then be aggregated and published in a paper entitled "Who's who in recommender systems" .
The shift from a pure algorithmic to a more user oriented focus on recommender systems research is something that seems to be gaining more and more interest in the research community today. In a speech given at Yahoo in 2004 Herlocker points out two issues missing in today's recommender system research, a uniform standard for evaluating recommender systems and a focus on user interfaces. John Riedl, another former member of the GroupLens team, wrote the year after in a foreword, published in connection with that year's ACM special issue on recommender systems [riedl05introduction] , that new algorithms only offers marginal improvements and that focus should now be on providing new ways for users of recommender systems to search, browse and better understand recommendations. These new capabilities will be realized trough new interfaces for recommender systems.